.
IT力とAI力
ここまで「人間の5元徳」そして「思考力」更に「マネジメント力」とお読み頂き誠にありがとうございます。これらの総仕上げとなるのが「経済活動」の解決策の「IT力とAI力」です。
この鍵が「普遍的勉強法」に基づく「メカ/エレキ/IT/AI」を統一的に開発する「汎用開発方法」であり、それをSysMLにより実装する「汎用開発ツール」であり、「思考の真理」に基づく「思考するAI」です。
これらをトップページで説明したように「コンピュータの真理」と「AIの真理」から説明します。具体的に言えば、「計算の真理」と「認識の真理」から「普遍的勉強法」に基づいて
説明します。そのため直感的にご理解頂けます。これを以下の順番で説明します。
1 IT力とAI力の根拠
1.1 サービス科学
1.2 自然科学のテクノロジの性能限界
1.3 人間の解く3種類の問題
1.4 最適化理論
1.5 IT
1.6 汎用開発方法/ツール
1.7 AI
1.8 CahtGPT
1.9 思考するAI
1.10 まとめ
2 IT力とAI力の実践知識
2.1 解くべき問題の本質を見抜く
2.2 汎用開発方法/ツールにより開発する
2.3 知能化製品/サービスを開発する
2.4 成功AIを開発する
2.5 まとめ
3 結語
4 皆様へのお願い
では次に「IT力とAI力の根拠」を説明します。
1 IT力とAI力の根拠
では「IT力とAI力の根拠」を説明します。既に目次でご覧頂ける通り、根拠として9項目を説明します。これは大変量が多いです。そのため最初に流れを全体的に説明し、この中で冒頭のポイントも説明します。
最初に「サービス科学」では先に説明したように「文明の利器を創造する科学は自然科学からサービス科学」に移行している事を説明します。そのため「サービス科学の本質」を自然科学と比較して説明します。これにより「サービス科学って何?」と疑問を抱かれてる方も多いと思いますが、直感的にご理解頂けます。
次に「自然科学のテクノロジの性能限界」では「なぜそうなのか」を説明します。つまり「なぜ自然科学からサービス科学なのか」を説明します。これは自然科学に基づくテクノロジの2つの限界のためです。1つは「性能限界」、もう1つは「発明限界」です。但し、このような理解は大変希薄です。そのため十分ご理解頂ければと思います。
さて以降、ITやAIを説明していきますが、その前に是非ご理解頂きたい事があります。それが「人間の解く3種類の問題」です。
このポイントは、現在IT化は「銀行のATMやコンビのPOS」などのように「処理の手続きが一義的に決定できる決定性の問題」から「囲碁・将棋などの指す手が膨大にあり一義的に決定できない非決定性の問題」に移行している事です。正にAIは「非決定性の問題」を解決するものです。
但し、ここで留意する事は「新たな概念を創造しなければ解けない問題」が存在する事です。それが「非可解の問題」です。これは「ITやAI」には解けない「創造力のある人間」にのみ解く事ができる問題です。
お分かり頂ける通り、「人間の解く問題」には「決定性・非決定性・非可解」と3種類あります。ここで「決定性・非決定性の問題」は「ソフトウエアの実行する方法論」つまりITやAIで解決し、「非可解の問題」には「人間の実行する方法論」が解決します。
次にご理解頂きたい事は「デジタル化」は「決定性の問題を解くIT」から「非決定性の問題を解くAIや最適化理論」に進展している事です。これが冒頭で説明した「経済活動の対象を見極める」のポイントです。
また「非可解の問題」を解く「人間の実行する方法論の一例」が「普遍的勉強法」や「最新経営理論」で説明した開発のPMや生産・流通のSCMや営業のCRMです。更に以降で説明する普遍的勉強法に基づく「汎用開発方法/ツール」です。れにより何を人間がやり、何をAIがやるのかを十分ご理解頂けると思います。
以降、ITとAIを説明します。最初に「IT」ではコンピュータの理論モデルを「計算の真理」と「計算の原理」から説明します。
あらかじめ説明すると「計算の原理」は「原理の方法論」と「手順の方法」から構成されます。ここで「原理の方法論」が「万能チューリングマシン」つまり「コンピュータ」です。「手順の方法」が「チューリングマシン」つまり「ソフトウエア」です。
また「計算の真理」は「数の真理」に基づきます。ここで「数の真理」を定めたのが「ペアノの公理」です。これを次に示します。
➀ 1は自然数
➁ 自然数には1を足した後者の自然数が1つ存在
➂ 異なる自然数の後者の自然数は異なる
ご覧頂ける通り、これは誰もが知ってる当たり前の事です。但し、この当たり前の事を正式に定義したのは19世紀です。それまでは特に数というもに対して人間は注意を払ってきませんでした。
ではこの「ペアノの公理」から生まれたテクノロジが何かをご存知ですか。そうですね。正に「コンピュータ」です。1936年のチューリングの論文では様々な数の計算を行いますが、チューリングは「数の発生器」として「ペアノの公理」を使用しています。これから「真理」から「テクノロジ」が生まれる事を改めてご理解頂ければと思います。
お分かり頂ける通り、「真理→原理→テクノロジ」として生まれたITを「価値→原理→手順」の「普遍的勉強法」に基づいて説明します。これにより「コンピュータ」も「ソフトウエア」も容易にご理解頂けます。
さて残り3つの項目がAIです。トップページでは詳細を省略しましたが、これらも「普遍的勉強法」に基づいて説明します。
あらかめ説明すると、ニューラルネットのメカニズムを全体的に説明し、次に画像認識を説明し、これを踏まえて言語認識の要となるアテンションを説明し、次にChatGPTのメカニズムを詳細に説明します。その後でChatGPTの限界を解決する私の発明した「思考するAI」の概要を説明します。これによりAIは大変難解ですが、十分ご理解頂けます。
その後で実践知識を順番に説明します。これらは前半の根拠から容易にご理解頂けます。
では次に「サービス科学」を説明します。
1.1 サービス科学
では次に「サービス科学」を説明します。つまり「文明の利器を創造する科学は自然科学からサービス科学へ移行している事」を説明します。これを次の図から説明します。
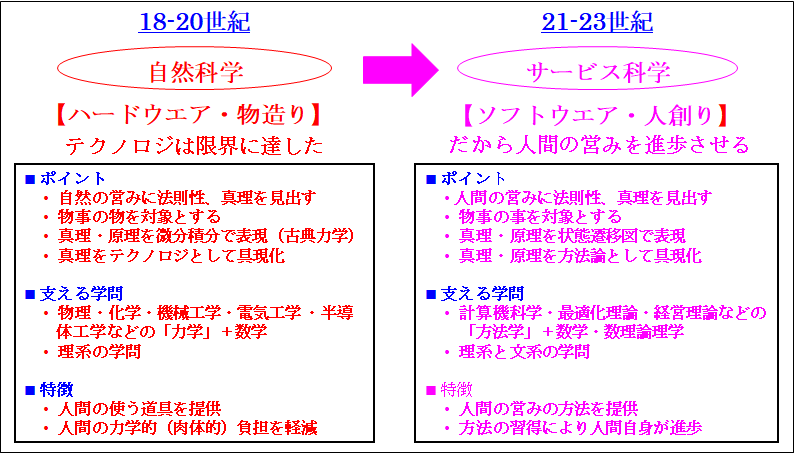
ご覧頂ける通り、「文明の利器」を「創造する科学」は「自然科学」から「サービス科学」に移行しています。このポイントは2点です。
1点目は「文明の利器」は「自然科学のハードウエア」から「サービス科学のメソドロジ(方法論)」に移行している事です。2点目は、「メソドロジ」による「テクノロジノ」の「IT化」更に「AI化」つまり「知能化」です。
最初に「自然科学とサービス科学の差」を説明し、次になぜ「テクノロジ」から「メソドロジ」に移行しているのかを説明し、最後に「知能化」を説明します。これを踏まえて2点目を説明します。
では「自然科学とサービス科学の差」を説明します。これは3点あります。1点目は、「自然科学」は「自然に営み」に真理、法則性を見出す科学です。それに対して、「サービス科学」は「人間の営み」に真理、法則性を見出す科学です。
そのため2点目は「自然科学は力学」ですが、「サービス科学は方法学」です。前者は「自然科学の発展」から明らかです。これは「ニュートン力学」→「マックスウエルの電磁方程式」→「量子力学」と発展してきました。「ニュートン力学や量子力学」の名称の通り、「自然科学」は「力学」です。
それに対して「サービス科学」は「方法学」です。これは「サービス科学」を支える主要な学問の「コンピュータサイエンス・最適化理論・経営理論・思考科学」からご理解頂けます。
「コンピュータサイエンス」が「方法学」である事は「コンピュータの理論モデル」を発表した1936年のチューリングの論文から分かります。チューリングは「コンピュータ」を「計算の汎用方法」と呼んでいます。「汎用方法」から「コンピュータサイエンス」は「方法学」をご理解頂けると思います。
次に「最適化理論」は「最適な方法」を求め、「経営理論」は「ヒト・モノ・カネを運用する方法」を求め、「思考科学」は「思考方法」を求めます。そのため「最適化理論・経営理論・思考科学」は「方法学」です。
そのため3点目は「サービス科学」の「成果物」は「メソドロジ、方法論」となります。ここで「方法論」は既に説明したように「人間の実行する方法論」と「ソフトウエアの実行する方法論」と2種類あります。
但し、あらかじめご理解頂きたい事は、共に「価値と原理と手順の統論」に基づきます。そのため両者を統一的に理解できるとご理解頂ければと思います。
では次に「自然科学のテクノロジの性能限界」を説明します。
1.2 自然科学のテクノロジの性能限界
では「自然科学のテクノロジの性能限界」を説明します。つまりなぜ「テクノロジ」から「メソドロジ」つまり「文明の利器」を「創造する科学」は「自然科学」から「サービス科学」に移行しているのかを説明します。
これは「自然科学に基づく文明の利器」は「限界」に達したためです。ここで「限界の意味」は2つあります。1つは「性能限界」、もう1つは「発明限界」です。
「性能限界」は直感的にご理解頂けると思います。過去数十年、自動車の最高速度は180km/h、電車は100km/h、飛行機は1000km/hです。自動車はポルシェのように時速300km/h近くのものもあり、また戦闘機には時速3,000km/h
近くのものもありますが、ほぼこれで限界です。また時速600 km/h のリニア新幹線も開発されていますが、飛行機の速度を超える事はありません。
これは急速に進化し続けてきたトランジスタ・LSIも同じです。遂にGHzで限界に達しました。この事は昨今使用され始めた「2つのCPUを使用するパソコン」や「数万個のCPUを使用するスーパーコンピュータ」更に「0と1の2値」しか扱えない現在のコンピュータから「50/100値を扱える量子コンピュータ」からご理解頂けると思います。「複数のCPUや多値の量子」を使用する事は「単一CPU」の性能限界を示しています。これはトランジスタ/LSIにより駆動される光通信も同じです。これもGHzで性能限界です。
お分かり頂ける通り、「自然科学に基づく文明の利器」つまり「ハードウエア」は「性能限界」に達しました。これは経済活動を営む上で非常に重要なポイントとなります。そのため十分ご理解頂ければと思います。
次に「発明限界」の意味は「自然科学の解き明かした真理から発明できる原理はすべて発明され、テクノロジとして具現化され、新たな原理を発明できない」という意味です。次にこの事を「チューリングの計算理論」、「ダンツグの線形計画法」、「染谷・シャノンのサンプリング定理」と併せて示します。
|
学問 |
年代 |
解き明かした真理 |
発明されたテクノロジ |
| ➀ニュートン力学 | 1687年 | 万有引力の法則と運動の法則 | すべての機械テクノロジ |
| ➁ベルヌーイの流体 工学の方程式 | 1738年 | 流体の位置エネルギーと運動エネルギーは互いに変換する | すべての流体の機械テクノロジ |
| ➂マクスウエルの電 磁方程式 | 1864年 | 電気は磁気を生み出し、磁気は電気を生み出し、電気と磁気は力を生み出す | すべての電気・電子テクノロジ |
| ➃アインシュタイン の相対性理論 | 1915-16年 | 物体の速度が光速に近づけば質量は無限大になる | 少ない。しかし、速度を延々と速くする事は無駄である事を教えている。 |
| ⑤アインシュタイン のレーザー理論 |
1917年 | 輻射の誘導放出による光増幅 | 半導体レーザー・光通信 |
| ⑥シュレーディンガ ーの波動方程式 | 1926年 | 電子は動いている時は波、停止すると粒子になる | 半導体トランジスタ・大規模集積回路 |
| ⑦チューリングの計 算理論 | 1936年 | 計算とは記号の状態の遷移 | コンピュータ |
| ⑧ダンツグの線形計 画法 | 1947年 | 経済活動には最適解が存在する | 生産・輸送最適化・ミクロ経済学 |
| ⑨染谷・シャノンの サンプリング定理 | 1949年 | アナログとデジタルは変換できる | 地デジ・CD・DVD |
| ⑩ディープラーニン グの近似解 |
2015年 | 誤差逆伝搬法により如何なる学習データの内部表現も抽出し認識/生成する近似解を求められる | 認識/生成AI |
ご覧頂ける通り、「自然科学」の解き明かした「真理」から「真理→原理→テクノロジ」の「近代化の精神」の通り、現代社会のすべてのハードウエアのテクノロジは発明されました。しかし、もうこれ以上「新たなハードウエアのテクノロジ」を創造する事はできません。
この理由は前述の通り、「自然科学」の解き明かした「真理」から、すべての「新たな原理」は発明され「テクノロジ」として具現化されてしまったためです。
次に「テクノロジの性能限界」に関連して、1点重要な知見を説明します。それは「アインシュタインの相対性理論」です。これは他の理論と比べると大規模な市場を生み出さなかった唯一の理論ですが、大変重要な事を教えています。
それは「永遠に速くする事」は「不可能」である事です。この理由は「物体の速度が光速に近づけば質量は無限大になるため」です。これを平たく言えば、「物には限界がある」という事です。
では「テクノロジ」が「性能限界」や「発明限界」に達したとして「人類」は「新たな富」をどのように生み出すのでしょう。これが「私が科学技術者として抱いた疑問」です。
そのため導いた「結論」が「サービス科学の方法論による富の創造」です。これは以降で説明するように「最適化理論」に基づく「私の経路最適化ソフトウエアの開発」が貢献しています。
このポイントは「経路」を「最適化」する事によりトラックの数を「2-3割削減できる事」です。ここで留意する事は「自動車の速度」は速めていない事です。つまり「テクノロジの性能」を高速化しなくても「テクノロジの使い方」を「最適化」する事により「新たな富」を生み出せる事です。これから「サービス科学の方法論による富の創造」という着想を得ています。
更に「最適化」は非常に重要な恩恵をもたらします。これが「地球温暖化防止」です。言うまでもなく、「地球温暖化防止」は人類の喫緊の課題です。率直に言って、「昨今の地球温暖化」は「20世紀までの自然科学のテクノロジ」に基づく「肥大化したエネルギー文明」が生み出したと考えています。そのためこれを解決するのが「サービス科学の方法論」と考えています。つまり「人々・社会の営み」を「最適化する事」です。
すなわち「最適化理論」や「ITやAI」により「エネルギー消費」を「最適化する事」です。これは十分可能です。そのため「太陽光発電や風力発電」と共に「サービス科学の方法論」も「地球温暖化防止」に大きく貢献できると考えています。このような理解、認識は希薄ですが、十分ご理解頂ければと思います。
では次に「人間の解く3種類の問題」を説明します。
1.3 人間の解く3種類の問題
では「人間の解く3種類の問題」を説明します。最初に感想を言えば、「経済活動」の対象となる「人間の解くべき3種類の問題」という表現に、「そのようなものが存在するのか」と疑問を抱かれる方も少なくないと思います。
しかし、存在します。この事をご理解頂くため、最初に「マネジメント力」で触れた「広義・狭義の経済活動」から「経済活動の対象の本質」を説明し、次に「人間の解くべき3種類の問題」を説明し、最後に「IT業界の開発動向」を説明します。これによりIT業界の大きな流れをご理解頂けます。
では「広義・狭義の経済活動」から「経済活動の本質」を説明します。既に「マネジメント力」の「正義化」で説明したように「広義の経済活動」は「正義化の原理」の通り、「問題定義+正義化1+正義化2」であり、「狭義の経済活動」は「問題解決活動」です。
そのため「経済活動の本質」は「問題解決」つまり「問題」です。そのため「人間の解くべき3種類の問題」を理解する事は「経済活動の出発点」です。これは十分ご理解頂けると思います。
では次に「人間の解くべき3種類の問題」を説明します。これを次の図から説明します。
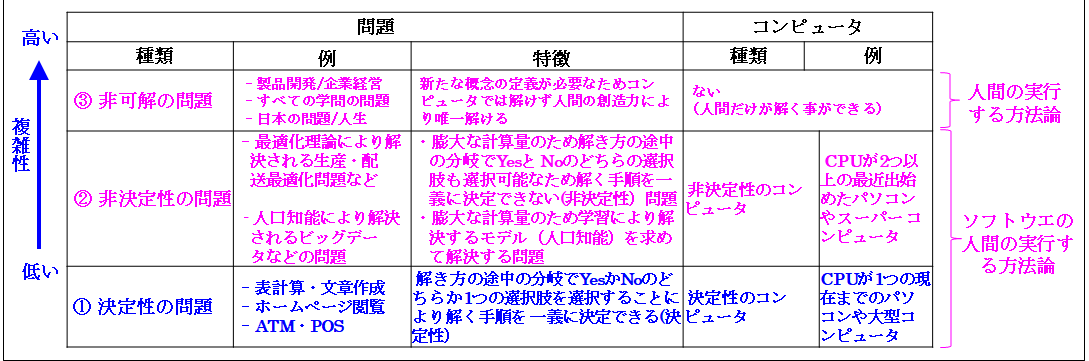
ご覧頂ける通り、「人間の解く問題」は既に説明している通り、①「決定性の問題」、②「非決定性の問題」、③「非可解の問題」と3種類あります。これは「コンピュータサイエンス」の解き明かした大変重要な「真理」です。そのため十分ご理解頂ければと思います。尚、以降は「問題」を説明すると共に「技術」も説明します。これにより身近に、また直感的にご理解頂けると思います。
最初に「3つの問題」を説明し、次に「なぜ2つの方法論が存在するのか」を説明し、最後に「現在のIT業界の開発動向」を説明します。
では①「決定性の問題」から説明します。これは「問題の範囲が限定的な為、解き方を一義的(決定性)に定義できる問題」です。ここで「問題の範囲が限定的」という文言は、次に説明する「非決定性の問題」との対比から使用する文言です。
この意味を分かり易く言えば、「問題の様々な事柄」をすべて「テーブルの上」に置けるという意味です。つまり「すべて見える」という意味です。また問題を解く時に、どちらか1つを選択しなければならない時に、明確に決定できるという意味です。そして日常生活のほとんどは「決定性の問題」です。
例えば、「80円の物を買って、100円玉を出せば、お釣りは20円」つまり「100円-80円=20円」と決定できます。また「100円玉」を出すか、「千円札」を出すかの選択肢がありますが、これも明確に決められます。そのため「解き方」を一義的に決定できます。これが「決定性の問題」です。
更に例を挙げれば、「学校のテスト」や「入学試験」です。これも既に学んだ「決まった手順を実行」します。尚、それを思い出せるかどうかは人により異なります。完全に理解している人は、学んだ通りに、つまり「決まった手順」を実行し問題を解く事ができます。
同様に「ITの視点」から言えば、「パソコンやスマホ」の処理している「表計算・文章作成やホームページ閲覧」も「ソフトウエア」は「決まった手順」を実行する事により「問題」を解いています。
つまり「入力されたデータ」に対して「表計算・文章作成・ホームページ閲覧」という「決まった手順」を実行し「求めるもの」を出力します。そのため「ソフトウエア」は「決定性の問題」を解いているという事になります。
但し、「ソフトウエア」の場合、「問題を解いている」と「理解、認識する事」に慣れていない方も多いと思います。この場合「出力」が「解答」に相当しますので「入力」が「問題」とご理解頂ければと思います。つまり「入力」という「問題」を受け取り「出力」という「解答」をするとご理解頂ければと思います。
次に「ハードウエアの視点」から言えば、「CPUが1個のコンピュータ」が「決定性のコンピュータ」です。そのため「誕生から現在までのコンピュータ」はすべて「決定性のコンピュータ」であり「決定性の問題」を解いています。このような説明は「初めて聞く」と感じると思いますが、そのように説明されれば、容易にご理解頂けると思います。
では次に②「非決定性の問題」を説明します。これは「問題の範囲が広大な為、解き方を一義的に決定できない(非決定性)問題」です。ここで「問題の範囲が広大」という意味は「決定性の問題」で説明した言葉で言えば、「すべて見る事ができない」であり「選択肢が膨大にあり決定できない」という意味です。
最初に「非決定性の問題の種類」を説明し、次に「解決策」を紹介します。では「非決定性の問題の種類」から説明します。現在開発中の主要な問題は①「最適化問題」、②「認識問題」、③「自動運転問題」と3種類あります。
①「最適化問題」の例は「グーグルマップ」の「最短経路問題」であり、先に説明した私が研究開発した「経路最適化問題」です。更に身近な例で言えば、「チェス・将棋・囲碁」です。
これらの特徴は「組み合わせ爆発」が発生する事です。これは「チェス・将棋・囲碁」からご理解頂けると思います。どの手を指すかは様々にあり「指し手の組合せ爆発」が発生します。そのためすべての指し手の組合せを数え上げる事もできませんし、どの選択肢を選ぶかも決定する事もできません。
次に②「認識問題」は「手書き文字認識/顔や動物などの画像認識/文章認識などの認識問題」です。これらの特徴も「際限のない膨大な数」が発生する事です。この事は「手書き文字や人の顔」からご理解頂けると思います。「人の書く文字」や「人の顔」は「膨大な数」です。この事も容易にご理解頂けると思います。
最後に③「自動運転問題」は「いつ何が起こるのか決定できない」という意味です。つまり「道路を走る車両の種類/込み具合」は時々刻々変わるため決定できません。この事も容易にご理解頂けると思います。
では次に「解決策」を紹介します。尚、詳しくは以降で説明します。①「最適化問題」の解決策は「最適化理論」です。次に②「認識問題」の解決策は「ディープラーニング」です。また③「自動運転問題」の解決策は「知能化」です。
次に「ハードウエアの視点」から言えば、「非決定性のコンピュータ」は昨今使用され始めた「2つのCPUを使用するパソコン」や「数万個のCPUを使用するスーパーコンピュータ」更に「0と1の2値」しか扱えない現在のコンピュータから「50/100値を扱える量子コンピュータ」です。
お分かり頂ける通り、「非決定性の問題」を解く「非決定性のソフトウエア」や「非決定性のコンピュータ」は計算量が膨大なため大変複雑で高度なものとなります。この事をあらかじめご理解頂ければと思います。
では最後に③「非可解の問題」を説明します。これは「新たな概念の定義」が必要なため、コンピュータや人工知能では解けず「人間の創造力」により解く問題です。この例は「製品開発」や「企業経営」であり「すべての学問の問題」であり「日本の問題」であり「人生」です。これらの問題を「コンピュータ」は解く事はできません。これは創造力のある人間のみが解く事ができます。この事は容易にご理解頂けると思います。
さて「人間の解く3種類の問題」を説明しましたので、次に「方法論」には「ソフトウエアの実行する方法論」と「人間の実行する方法論」と2種類ある事を説明します。
これは既に推察できると思います。「ソフトウエアの実行する方法論」が①「決定性の問題」と②「非決定性の問題」に対応し、「人間の実行する方法論」が③「非可解の問題」に対応します。この事は容易にご理解頂けると思います。
では最後に「IT業界の開発動向」を説明します。これも既に推察できると思います。現在のIT業界の開発動向は「決定性の問題」から「非決定性の問題」に移行しています。この代表例が「ディープラーニング」であり、「ハードウエア」で言えば、「量子コンピュータ」です。この事も容易にご理解頂けると思います。
さて以上の説明からご理解頂きたい事は、今まで人間しか解けないと思われていた問題は
多くが「非決定性の問題」である事です。またテストは「決定性の問題」であり、基本的に「価値→原理→手順lと完全に理解しているならば、誰でも解ける事です。これを誤解しないで欲しいという事です。
AIによる司法試験や医師の国家試験の合格また文章の生成など、一見人間の能力を実現したと錯覚しがちですが、そうではないという事です。この事を十分ご理解頂ければと思います。
では次に「最適化理論」を説明します。
1.4 最適化理論
では「最適化理論」を説明します。先に説明したように「最適化理論」は「非決定性の問題」を解きます。
最初に「非決定性の問題の特徴」から説明します。これは次に示す通り、「膨大な状態が発生する事」です。
|
種類 |
組み合わせ数 |
|
70の配送先 |
10100 |
|
チェス |
10120 |
|
将棋 |
10220 |
|
囲碁 |
10360 |
ご覧頂ける通り、「70の配送先」は10100、「チェス」は10120、「将棋」は10220、「囲碁」は10360と「膨大な組み合わせ数」が発生します。
例えば、配送先が70カ所の場合「70の階乗」の「組み合わせ」が発生します。この理由は出発する時は70の選択肢があり、次ぎに69の選択肢があり、そして68、67・・3・2・1となり全部で「70の階乗」となるためです。
では、これはどのくらいの大きさかと言うと、1.2x10100です。仮に1GHzのコンピュータで109通りの経路の計算を1秒間でしたとしても、計算の終了するのは3.8x1083年かかります。宇宙が誕生して138億年、つまり138x108年ですので、3.8x1083年はとてつもない時間です。
お分かり頂ける通り、「非決定性の問題」の特徴は「膨大な組み合わせ数」が発生する事で。そのため2つ目の特徴は「唯一絶対正しい厳密解(最適解)」を求めるのは難しいため「最適解」に近い「近似解」を求めます。
つまり「精度」が「100%」ではなく「99%未満の近似解」を求めます。これは「配送問題・チェス・将棋・囲碁」や「手書き文字/画像/言語認識」つまりAIも含めてすべて同じです。
そのため従来「一義的」に「唯一絶対正しい厳密解」を求めていた「決定性の問題」とは「解き方」が大きく異なります。このポイントは「不等号の数学」や「要素を抽出・認識・学習する数学」を用いる事です。尚、これらは以降で説明します。
最後に3目点の特徴は「非決定性の問題」は「人間の営み」にのみ存在し、「自然界」には存在しない事です。これは「配送問題・チェス・将棋・囲碁・手書き文字/画像/言語認識」からご理解頂けると思います。
これを「決定性の問題」を解く「等号の数学」と対比して言えば、「自然の営み」を解明する「ニュートン力学やマックスウエルの電磁方程式やシュレーディンガーの波動方程式」は、例えば「力(f)=質量(m)x加速度(α)」、「f=mα」の通り、すべて「左辺(f)」と「右辺(mα)」を「=、等号」により関係付ける「等号の数学」により解きます。
そのため「3つの変数」の中で「2つが分かって」いれば「残りの1つ」を「唯一絶対正しい厳密解(最適解)」として「一義的」に求める事ができます。これが「決定性の問題」のポイントです。
それに対して「人間の営み」から生まれる「非決定性の問題」では「不等号」により解きます。この理由は「人間の営み」には「様々な制約」が存在するため「制約」を満たす事が不可欠なためです。
例えば、「4トントラック」に「8トンの荷物」を積載する事はできません。そのため「積載制約<4トン」と定義し、この「制約」を満たすように「近似解」を求めます。更に様々な「制約」が存在します。これらの「制約」を「不等号の数学」により定義する事が「最適化問題」では必須となります。
まとめると「非決定性の問題」の特徴は①「膨大な状態が発生する事」、②「近似解を求める事」、③「人間の営みにのみ存在する事」です。十分ご理解頂ければと思います。
では次に「不等号の数学」としての「最適化理論」を説明します。これを次に示します。
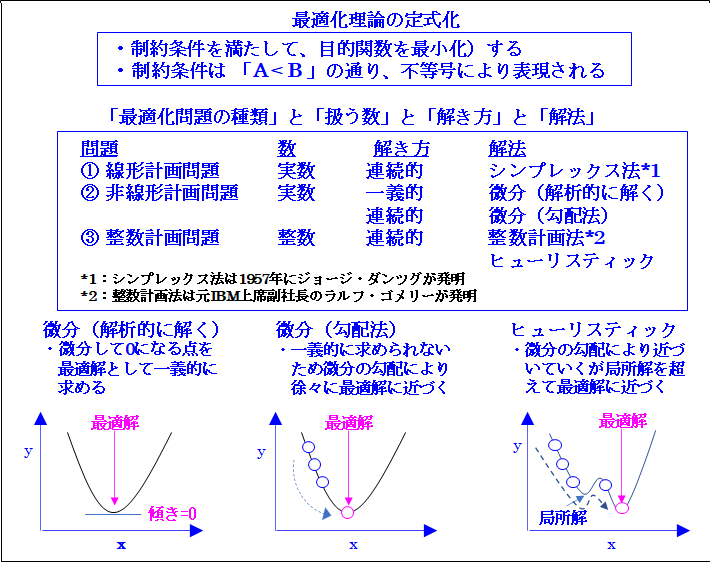
ご覧頂ける通り、「最適化理論の定式化」は「A<B」の通り、「不等号」により表現される「制約条件」をすべて満たし「目的関数」を最小化する「最適解」を求める形で行われます。これが「最適化理論」は「不等号の数学」を用いるという意味です。
最初に最適化理論の誕生から説明します。これは「線形計画問題」を解く「線形計画法(シンプレックス法)」を1947年に「ジョージ・ダンツグ」が発明した事が始まりです。「ジョージ・ダンツグ」は著作で「過去2000年の数学」は「等号の数学」であり「線形計画法」などの「最適化理論」は「不等号の数学」と説明しています。
これは「慧眼」であり、これから「非決定性の問題を解くのが不等号の数学」、「決定性の問題を解くのが等号の数学」と定義しています。
では次に「最適化問題の種類」と「扱う数」と「解き方の特徴」と「解法」を説明します。最初に「最適化問題の種類」は①「線形計画問題」、②「非線形計画問題」、③「整数計画問題」と3種類あります。
①「線形計画問題」は「扱う数」が「実数」のみで「目的関数または制約」などが「y=ax+b」のように「線形、つまり直線」で表現されるものです。次に②「非線形計画問題」の「目的関数や制約」などが「直線」ではなく「曲線」です。
最後に③「整数計画問題」は扱う数が「整数」の場合です。この例は「配送問題」や「チェス・将棋・囲碁」です。「配送」は「トラックを3.2台」と最適化できません。つまり「トラック」は1台、2台と「整数」で表現され、また「チェス・将棋・囲碁」も一手、二手と「整数」で表現されます。これが「整数計画問題」です。
次に「解き方の特徴」は「簡単な場合」と「面倒な場合」と「難しい場合」の3つあります。
「簡単な場合」は従来の「等号の数学」と同様に「人間の計算」により「一義的」に「最適解」つまり「厳密解」を求めます。
次に「面倒な場合」は「人間の計算」により「一義的」に求める事はできませんが、何回も人間が操作を行う事により「最適解」を求めます。
最後に「難しい場合」は、最初に「制約」を満たす解(実行解)を求め、次に更に良い解(近似解)を連続的に求めて行くやり方です。この場合は「最適解」を求める事は膨大な時間がかかるため「近似解」を求めます。また人間の計算では不可能な為「コンピュータ」により行います。
次に「解法」は①「線形計画問題」に対しては「ジョージ・ダンツグ」が発明した「シンプレックス法」があります。これは「面倒な場合」ですが、難しくはなく、実行解を求め、次に連続的に「最適解」を求めます。
次に②「非線形計画問題」の「解法」は「簡単な場合」と「難しい場合」の2種類あります。「簡単な場合」は「微分」つまり「微分」して0になる点を「最適解」として一義的に求めます。「難しい場合」は「微分の勾配法」により「近似解」を求めます。これは後半で説明する「ディープラーニング」でも使用されます。ご記憶頂ければと思います。
最後に③「整数計画問題」の「解法」はラルフ・ゴモリ― 元IBM上席副社長が発明しました。これが「整数計画法」です。但し、「問題規模」が大きくなると、計算には「何百億年」をはるかに超える途方もない時間がかかります。
そのためこれを解決するのが「ヒューリスティック」です。これは「難しい場合」です。つまり「局所探索法」などのアルゴリズムにより「局所解」から更に「最適解」に近づく方法です。
ここで「最適化理論」と「私」の関係について説明します。先に説明したように、私は40才までは液晶、光磁気ディスクというハードウエアの研究開発を行い、40才から「拙著」を執筆するため退職した57才までは「経路最適化ソフトウエア」と「モデリング言語」の研究開発を行いましたが、「経路最適化ソフトウエア」として研究開発したのが「ヒューリスティック」です。
この理由は「ある大手自動車会社の輸送規模」が非常に大きく「整数計画法」により「当時の最も高速のIBMの並列コンピュータ」で24時間計算しても「初期解」すら求める事ができなかったためです。これには非常に驚くと共に「最適化問題の恐ろしさ」というものを実感しました。多くの皆様はこのような経験はないと思いますが、十分ご理解頂ければと思います。
そしてこれはAIも同じです。膨大な計算を行います。これは「非決定性の問題」の特徴です。率直に言って、私もそうでしたが、今までは全て「決定性の数学」を学んできました。この特徴は人間が計算できる事です。
しかし、「非決定性の問題」はそうではありません。人間にはとてもできるものではありません。計算量は膨大です。これはAIの大きな特徴です。そのため十分ご理解頂ければと思います。
では次に「IT」を説明します。
1.5 IT
では「IT」を説明します。先に説明したように「普遍的勉強法」に基づいてコンピュータの理論モデルの「計算の原理」を「原理の方法論」と「手順の方法」として説明します。そのため容易にご理解頂けます。これを「ITのポイント」として次の図から説明します。
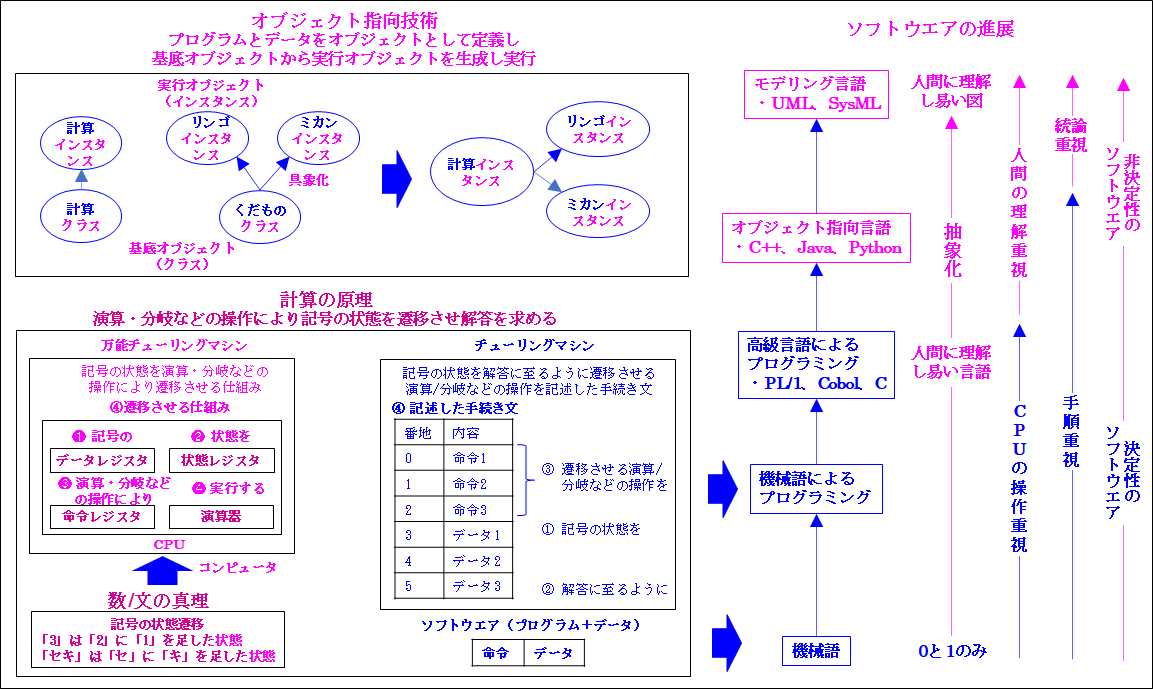
最初に基本となる「計算の真理」を説明します。これは「3は2に1足した状態」であり「セキはセにキを足した状態」です。つまり「計算の真理」は「記号の状態遷移」です。
これから「記号の状態を演算/分岐などの操作により遷移させ解答を求める仕組み」という「計算の原理」つまり「コンピュータの理論モデル」が導かれます。このポイントは「計算の原理」は「原理の方法論」と「手順の方法」に分離できる事です。
つまり「原理の方法論」が「コンピュータの理論モデル」の「万能チューリングマシン」であり「コンピュータ」に相当します。また「手順の方法」が「チューリングマシン」であり「ソフトウエア」に相当します。これが「コンピュータとソフトウエアの関係」です。
では次に具体的に説明します。「万能チューリングマシン」は「記号(①)の状態(②)を演算・分岐などの操作(③)により遷移させる仕組み(④)」です。これは「コンピュータの心臓部」の「CPU」の❶「データレジスタ」、❷「状態レジスタ」、❸「命令レジスタ」、❹「演算部」により実行されます。
処理の流れは、最初に①「記号」を❶「データレジスタ」に保管し、次に②「状態」を❷「状態レジスタ」に維持し、更に③「演算・分岐などの操作」を❸「命令レジスタ」にセットし、最後に❹「演算部」で実行させる仕組みが④「記号の状態を遷移させる仕組み」の「万能チューリングマシンでありコンピュータ」です。
次に「チューリングマシン」は「記号の状態(①)を解答に至るように(②)遷移させる演算/分岐などの操作(③)を記述した手続き文(④)」です。
つまり①「記号の状態」を「コンピュータのメモリ」にストアし、次に②「解答」に至るように③「遷移させる演算/分岐などの操作」を④「記述した手続き文」です。これから「チューリングマシン」は「ソフトウエア」であり、これは「万能チューリングマシン」つまり「コンピュータ」の「操作」を用いて実際に計算や文章の作成を行う事をご理解頂けると思います。
さて、以降は「ソフトウエア」に力点を置いて説明しますが、あらかじめ2点、素朴な疑問に答えておきたいと思います。これは①「そもそも計算ができるのは何故か」、②「1円の円を理解してるのは誰か」です。これにより「コンピュータ」と「ソフトウエア」を更に深くご理解頂けます。
では①「そもそも計算ができるのは何故か」から説明します。これは「数の真理」が定義された為です。具体的に言えば、「1、2、3などの自然数」については「ペアノの公理」、また「1.1などの実数」については「デデキントの切断」です。
ここでご理解頂きたい事は2点です。1つは、チューリングは1936年の論文で両者に基づく「数」を使用する事により「万能チューリングマシン」と「チューリングマシン」により計算が可能となった事です。そのため両者の実装として現在は「0と1」の「2進数」をコンピュータは採用していますが、それが「コンピュータ」を生み出したのでなく「数の真理が生み出した」とご理解頂ければと思います。
もう1つは「数の真理」のように「対象の真理」が定義されなければ、つまり分からなければ「ソフトウエア」で「対応するしかない」という事です。この一例が「文字の意味」です。「文字の意味」を統一的に定義する「真理」は見つかっていません。そのため「対象毎」に「文字の意味」を「ソフトウエア」で定義します。
そのため②「1円の円を理解してるのは誰か」の解答は「ソフトウエア」となります。つまり「コンピュータ」は「数」は理解していても「円」という「文字の意味」を理解していません。これを理解しているのは「ソフトウエア」です。
そのため「ソフトウエア」は「対象」を理解するために前述の「記号の状態を解答に至るように遷移させる演算/分岐などの操作を記述した手続き文」という役割と共に「オブジェクト指向技術」のように「意味の一貫性を維持する機能を備える必要がある」とご理解頂ければと思います。
尚、正確に言えば、「ソフトウエア」も「人間」と同じように「円」の「意味」を理解している訳ではありません。つまり「日本の金の単位」という「意味」を理解していません。更に言えば、「円い」という「意味」も理解していません。
そうではなく「くだものを具象化したものがミカンとリンゴ」という「意味の一貫性」、「セマンティック」を理解しているだけです。これを「くだもの」と「ミカン」と「リンゴ」という「記号の一貫性」、「シンタックス」により実現しています。そのため「果物」や「蜜柑」や「林檎」という「文字」は使用できません。あくまでも「くだもの・ミカン・リンゴ」という「文字」を使用する事が必要です。
お分かり頂ける通り、「セマンティック」、「意味論」と「シンタックス」、「統語論」を理解、実践する事は「ソフトウエア」では必須の要件です。そのため「円の意味」と「円の記号」から「セマンティックとシンタックスの重要性」をご理解頂ければと思います。
では次に「ソフトウエアの「本質と種類」と「記述言語の形式と発展」を説明します。理解する』です。
最初に「ソフトウエアの定義」から説明します。これは「ソフトウエア=データ+プログラム」です。この事は先に説明した「記号の状態遷移」からご理解頂けれると思います。つまり「記号」、「データ」を「状態遷移」させるのが「ソフトウエア」です。これは「データ」と「状態遷移させるプログラム」から構成されます。そのため「ソフトウエア=データ+プログラム」となります。
次に「プログラムの本質」は「アルゴリズム」です。ここで「アルゴリズム」はあたかも「ベルトコンベヤ」に乗って「記号の状態」が「解答」に「自動的に到達する手順」です。この事は前述の「記号の状態を解答に至るように遷移させる」からご理解頂けると思います。
尚、あらかじめ説明すると「アルゴリズム」は「決定性の問題」では難しくはありませんが「非決定性の問題」では大変難しくなります。つまり最適化理論やAIの「アルゴリズム」のように大変難しくなります。この理由は菩提なデータと計算を行うため多くの計算式などの数学を使用するためです。
次に「ソフトウエアの種類」は「OS・ミドルウエア・アプリ・開発ツール」と4種類あります。ここで「OSとアプリ」はご存知と思います。「ミドルウエアと開発ツール」は「アプリ」を支援するものです。
つまり「アプリ」が「データ」の保管や検索をする時に支援するミドルウエアが「RDB、リレーショナル・データ・ベース」です。またインターネットなどの通信を支援するミドルエアが「通信ソフト」です。
次に「開発ツール」は「プログラミング言語」や「モデリング言語」またこれらをコンピュータが実行する形に変換する「コンパイラ」や「言語やコンパイラと開発環境」を統合した「開発ツール」です。
「開発ツール」は「誰もがソフトウエアを開発できる」ために非常に重要な道具です。以降で説明するように「汎用開発方法」を「開発ツール」として具現化したものが「汎用開発ツール」です。
では次に「ソフトウエアを記述する言語の形式と発展を理解する」を説明します。最初に「ソフトウエアを記述する言語の形式」は前述の「ソフトウエアの本質」の「データ+プログラム」や「チューリングマシン」の「記号の状態を遷移させる操作」→「記号への操作」つまり「命令+データ」からご理解頂けると思います。
次に「ソフトウエアを記述する言語」は「機械語→高級言語→オブジェクト指向言語→モデリング言語」と発展しています。「機械語」は「操作(CPUの命令セット)」を「言語」の視点から表現した言語です。これは「コンピュータ」つまり「機械」のみが理解できる言語です。そのためこれに基づくプログラミングは「機械語によるプログラミング」と呼ばれます。但し、これは「1と0」のみのため人間が理解するのは容易ではありません。
そのため理解し易い「C」などの「高級言語」が開発されました。但し、これらはCPUの操作を重視したものであり、「CPUの専門知識」が必要です。しかし、「CPUの専門知識」は「計算」には不要です。
そのため「人間に直感的に理解し易い技術」として「ソフトウエア工学」の視点から開発された技術が「オブジェクト指向技術」であり、「C++、Java、Python」などの「オブジェクト指向言語」です。
「オブジェクト指向技術」では「プログラム」と「データ」を「オブジェクト」として定義し、「基底オブジェクト」から「実行オブジェクト」を生成し実行します。尚、「基底オブジェクト」は「クラス」と呼ばれます。例を挙げれば、「リンゴ」と「ミカン」を「抽象化」した「くだもの」です。
次に「実行オブジェクト」は「くだもの」を「具象化」した「リンゴ」や「ミカン」です。これが「実行中のプログラム」です。これは「インスタンス」と呼ばれます。この理由は「基底オブジェクト」から「生成」、「インスタンシエーション」されるためです。
これは「計算プログラムオブジェクト」も同じです。「計算クラス」から「計算インスタンス」を生成し「リンゴインスタンス」と「ミカンインスタンス」にアクセスし計算します。
ここで「基底オブジェクト」と「実行オブジェクト」が先に説明した「対象を理解する仕組み」です。十分ご理解頂ければと思います。
更に理解し易くしたものが「モデリング言語」です。これは「プログラミング言語」のように「命令」を記述するのではなく既に説明したように「図」を使用します。これにより人間に理解し易くなり、「命令を記述するプログラミング量」は膨大ですが、大幅に削減できます。
更に加えてもう1つの利点は、既に説明したように「モデリング言語」から「プログラム」を「自動的に生成できる事」です。
そのため「汎用開発方法/ツール」は「モデリング言語」を使用します。これを一般的に言えば、「手順重視のプログラミンング」から「価値→原理→手順」に基づくモデリング」です。
つまり「ソフトウエア技術」は「オブジェクト指向技術」の通り、「人間が容易に理解できる」ように発展した事です。すなわち「使い易さ重視」で発展してきた事です。この延長上に「価値→原理→手順」に基づく「モデリング言語」があるとご理解頂ければと思います。
では次に「汎用開発方法/ツール」を説明します。
1.6 汎用開発方法/ツール
では「汎用開発方法/ツール」を説明します。これは「価値→原理→手順」に基づく「モデリング言語」を採用します。これを次の図から説明します。
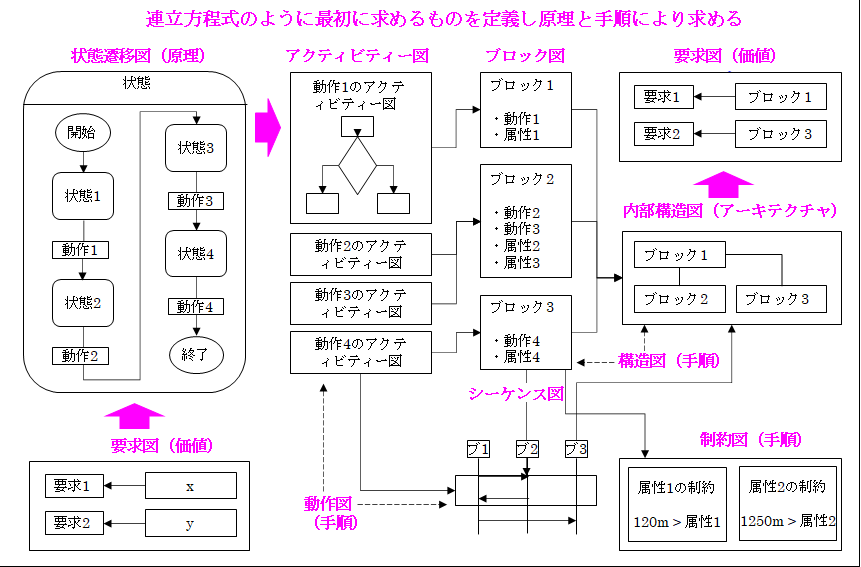
ご覧頂ける通り、「汎用開発方法」は、最初に求める「価値」を「要求図」により定義し、次に「原理」を「状遷移図」により定義し、最後に「手順」を「アクティビティ図」や「シーケンス図」などの「動作図」により定義します。
尚、「汎用開発方法」はモデリング言語として「ソフトウエアのモデリング言語」で説明したようにSysMLを使用します。また「汎用開発方法」に基づく「開発ツール」が「汎用開発ツール」です。
次に「動作」を実行する「プログラム」を[ブロック図」や「内部構造図」により定義し、またプログラム実行時の「物理的・論理的制約」を「制約図」により定義します。
次にSysMLでは先に説明した「ソフトウエア・オブジェクト」の「クラス」や「メカ・エレキ」の「コンポーネント」も「ブロック」として統一的にモデリングします。そのため「ソフト/家電/自動車」などを「汎用開発方法/ツール」により統一的に開発できます。
尚、「汎用開発方法」は今回のホームページ作成のため私がIBM時代に行ったSysMLのコンサルの体験から導きました。但し、その時はまだこれを発明できませんでした。そのためこのお客様には大変感謝しています。
さてSysMLを用いた「汎用開発方法/ツール」の説明は以上の通りですが、ここでモデリング言語について素朴な疑問に答えたいと思います。
これは①「プログラミング言語には存在しない原理を表現する状態遷移図がなぜ存在するのか」、②「モデリング言語はなぜ普及しないのか」、③「自動運転のように、いつ何が起きるのか分からない状態の遷移をどのようにモデリングするのか」です。
これによりソフトウエアを更に深くご理解頂けると共に「非決定性の問題」を解く「知能化製品の原理」の「基本的考え」をご理解頂けます。そのため十分ご理解頂ければと思います。
では①「プログラミング言語には存在しない原理を表現する状態遷移図がなぜ存在するのか」から答えます。
最初に「原理を表現する状態遷移図」と「プログラミング言語」との「矛盾」から説明します。これは明らかです。「プログラミング言語」は先に説明したように「操作を記述した手続き文」であり、その本質は「手順」であり「原理」ではありません。
ではなぜ「原理を表現する状態遷移図」をモデリング言語に導入するのかといえば、2つの理由があります。
1つは「複雑な事」を理解し易くするためです。例えば、「1-2時間で登れる山」には「富士山」のように「1合目→2合目・・→10合目」という「方法論」つまり「原理の方法論」すなわち「原理」はありません。そうではなく「道筋」つまり「手順の方法」すなわち「手順」のみで十分です。
次に「ソフトウエア」、「IT」の進展を見れば、益々複雑、高度になってきています。しかし、「コンピュータ」は並列化などにより高速化できても「理解しているの」は相変わらず「数」だけです。つまり「複雑、高度な事」を理解しません。
ではどうするのかと言えば、先に②「1円の円を理解してるのは誰か」で説明したように、ソフトウエアで対応せざるを得ません。そのためソフトウエアで対象を理解し易くするために「原理を表現する状態遷移図が使用される」とご理解頂ければと思います。
但し、「モデリング言語を具象化したもの」が「プログラミンング言語」です。では「原理を表現する状態遷移図」は「プログラミンング言語」では何に変換されているのでしょう。
これが「操作」の「演算/分岐」の「分岐」です。一例を挙げれば、「if then else」です。つまり「もし、何々(という状態)ならば、何々する。そうでない(状態)ならば、何々する」という「分岐」です。これが変換されたものです。
しかし、「複雑な事」を処理する時は、「if if if・・」のように「if」が連続してしまいます。そのため本人でも理解するのが大変面倒、また日が経てば忘れてしまいます。この根本原因は「if」を「一行、一行書く」という「プログラミング言語」の本質にあります。
それに対して「図」を用いる「状態遷移図」は容易に理解できます。これがもう1つの理由です。つまり「オブジェクト指向技術」のように「理解し易くするため」です。これが「原理を表現する状態遷移図」を「複雑な処理」に適用する利点です。
さて、ここで普及状況を説明すると、「良い事づくめのモデリング言語」ですが、「普及」は進んでいません。そのため次に②「モデリング言語はなぜ普及しないのか」を説明します。
これは前述の説明から推察できると思います。「プログラミング言語」は「計算」などの手順を記述するものです。そして「コンピュータ」つまり「計算機」から容易にご理解頂ける通り、誕生から現在まで「計算」という「手順を記述する事」が「ソフトウエア開発の主業務」となっていたためです。
例えば、「ATM」は、正に「預貯金」という「手順」を行うものであり、「レジのPOS端末」で行うのも「手順」です。更にはホームページも「閲覧」という「手順」を行うものです。但し、「今後」は異なります。前述の通り、複雑な処理にはモデリング言語は必須です。そして「増々複雑化」しているからです。そのため今後は「モデリング言語」は必須の要件とご理解頂ければと思います。
では最後に③「自動運転のように、いつ何が起きるのか分からない状態の遷移をどのようにモデリングするのか」を説明します。この解答は「モデリング言語の拡張」です。現在のモデリング言語は「いつ何が起きるのか分からない状態の遷移」には対応していません。これは以降で説明します。ご理解頂ければと思います。
まとめると「IT」として「計算の真理」と「計算の原理の方法論」と「手順の方法」と具現化されたものとして「コンピュータ」と「ソフトウエア」を説明しました。またソフトウエアの「本質と種類」と「記述言語の形式と発展」そして「モデリング言語と統論」に基づく「汎用開発方法/ツール」を説明しました。十分ご理解頂けたと思います。また「真理と原理」に基づく説明は理解し易い事もご理解頂けたと思います。
では次に「AI」を説明します。
1.7 AI
では「AI」を説明します。最初にディープラーニングに慣れて頂くために「原理の方法論」と「手順の方法」により全体の流れを説明します。ここでニューラルネットのパラメーターを調整する「誤差逆伝搬法」を「微分」に基づいて正確に説明します。これは以降で非常に重要なものとなります。そのため十分ご理解頂ければと思います。
次にディープラーニングを具体的に説明します。最初に画像認識から説明し、次に言語認識を説明します。言語認識では「トークン化/エンベッディング/アテンション」の3つのメカニズムを説明します。これにより「ChatGPT」も理解し易くなります。併せて何故ChatGPTが必要になってきたのかの背景も説明します。
では「ディープラーニングの認識」の「原理の方法論」と「手順の方法」を次の図から説明します。
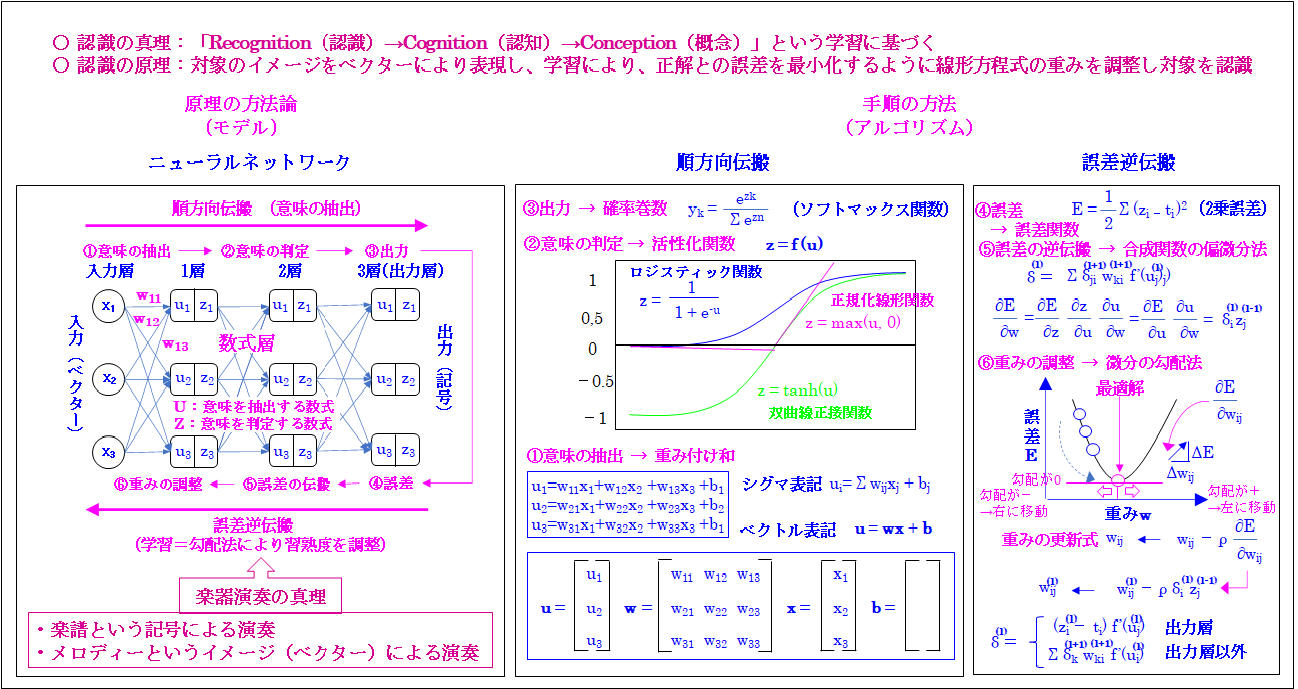
ご覧頂ける通り、「ディープラーニングの認識」も「原理の方法論」と「手順の方法」に基づいています。但し、これらの説明は「即、専門的な説明」となります。そのため最初に「ディープラーニングのポイント」を説明し、次に「原理の方法論」と「手順の方法」を説明し、最後に「まとめ」を説明します。
では「ディープラーニングのポイント」を説明します。これはディープラーニングでは学習を「正解」を与え「認識の出力」との「誤差」を最小化するように「ベクトルの重み」を調整する事により行います。そのため「対象」を「ベクトル」により表現し、学習により、正解との誤差を最小化するように「線形方程式の重み」を調整し対象を認識」します。
これは次に説明する「ディープラーニングの認識」の「原理の方法論」を要約したものです。では次に「ディープラーニングの認識」の「原理の方法論」を説明します。
「原理の方法論」は先に説明した「富士山登山」の「1合目→・・10合目」の通り、「状態を遷移させる仕組み」です。そのため「ディープラーニングの認識」にも「1合目→・・10合目」の通り「状態」があります。
これは「2つの状態」に分かれます。1つは「学習」、もう1つは「認識」です。次に「学習」は「順方向伝搬」と「誤差逆伝搬」の「2つの状態」に分かれます。
「順方向伝搬」の「状態」は①「要素の抽出」→②「要素の判定」→③「出力」の「3つの状態」に分かれます。尚、「認識の時の出力」は「ベクトル」から「記号」に変換されます。それに対して「学習の時の出力」の「ベクトル」は次に説明する④「誤差の計算」への入力となります。図ではこの事を省略していますが、ご理解頂ければと思います。
次に「誤差逆伝搬」は④「誤差の計算」→⑤「誤差の逆伝搬」→⑥「重みの調整」 の「3つの状態」に分かれ」ます。そのため「学習」は「順方向伝搬」と「誤差逆伝搬」と合わせて「6つの状態」により行われます。
これらを「ニューラルネットワーク」により実行します。図では「3つのニューラルネットワーク」が使用されています。そのため①「要素の抽出」から⑥「重みの調整」は3回行われます。次に「ニューラルネットワーク」を一言で言えば、「数式層」です。ここでは「6つの状態」に応じて「6つの数学」が使用されます。
まとめると「原理の方法論」として図では「原理」の「6つの状態」が存在し、それらに応じる「6つの数学のアルゴリズム」が「手順」として存在するという事です。この事をあらかじめご理解頂ければと思います。これは以降で説明します。
ここでは要となる「2つの数学」をあらかじめ説明します。これは「ディープラーニング」の「習熟度」を「状態遷移させる仕組み」となるのが「順方向伝搬」で使用される❶「学習の進捗度を表現する数式」と「誤差逆伝搬」で使用される❻「習熟度を調整する微分の勾配法」です。
➊「学習の進捗度を表現する数式」は以降で説明するように「u = wx + b」という線形関数であり、「グラフ」にすれば「直線」となる関数であり「要素を抽出するもの」ではありません。
但し、もし「w」が❻「習熟度を調整する微分の勾配法」により「0.1から0.9」に調整された場合はどうでしょう。この場合、「b」を省略した簡略式の場合、「u = 0.1xとu = 0.9x」となり、両者は大きく異なります。
例えば、「x=1.0」の場合「w」が「0.1」の時は「u = 0.1X1.0=0.1」、「w」が「0.9」ならば、「u = 0.9X1.0=0.9」となります。
つまり「0.1対0.9」となり「有意な差」となります。ここで「活性化関数の閾値」を「0.5」として「0.5以下を0、以上を1」と仮定すれば、「0.1→0」それに対して「0.9→1」つまり「0対1」となり「要素を抽出する事」が可能となります。
すなわち「正解」を与える事により「出力」が「1.0」となるように「w」を「0.1から0.9」に❻「習熟度を調整する微分の勾配法」により徐々に調整する事により「u = wx + b」が「要素を抽出する数式」となる事をご理解頂けると思います。
では次に「ディープラーニングの認識」の「手順の方法」として具体的に説明します。先に説明したように「アルゴリズム」はあたかも「ベルトコンベヤ」に乗って「記号の状態が解答」に「自動的に到達する手順」です。
ここで「ディープラーニング」では「記号の状態」が「ベクトルの状態」に代わります。また「自動的に到達する手順」は前述の「6つの数学のアルゴリズム」により行われます。
最初に「順方向伝搬」の①「要素の抽出」では、❶「学習の進捗度を表現する数式」により「入力のベクトル、x」から「要素を抽出する数式」の「u = wx + b」、正確に言えば、「u1=w11x1+w12x2 +w13x3 +b1」により、前述の通り「要素」を抽出します。
次に②「要素の判定」では出力の「u」は❷「活性化された状態を表現する数式」に入力され「z = f (u)」の通り、閾値を超えれば「活性化された状態」になります。ここで「活性化関数」は「ロジスティック関数・正規化線形関数・双曲線正接関数」などがあります。これは以降で説明するように「微分可能」である事が必要です。以降、同様な操作を2回繰り返されます。
最後に③「出力」では「ソフトマックス関数」などの❸「答えの確率を表現する関数」により「解答」を出力します。
次に④「誤差の計算」では、この「解答」と「正解」の「誤差」を「2乗誤差」などの❹「誤差を表現する関数」により表現します。
次に⑤「誤差の伝搬」では❺「誤差を逆伝搬する合成関数の偏微分法」により誤差を伝搬します。
最後に⑥「重みの調整」では❻「習熟度を調整する微分の勾配法」により「誤差」が小さくなるように「w(重み)」と「b(バイアス)」を調整し、再度、異なる入力データに対して同様な操作、つまり学習を行い「誤差」が十分小さくなれば「学習」は終了し、実際に使用します。
ここで「順方向伝搬」の➊から❸と「逆誤差伝搬」の❹は容易にご理解頂けると思います。しかし、「逆誤差伝搬」の❺と❻は理解し難いと思います。そのため最初に基本となる考えを説明し、次に具体的に説明します。
最初に基本となる考えは、先に最適化理論で説明した「微分の勾配」により徐々に最適解に近づく事です。この場合、最適解は「誤差最小化」です。そのため「誤差」が最小化するように「重み、w」を調整します。
ここで「微分の勾配」の意味は「微分して求めた勾配、傾き」という意味です。これは3つに分かれます。
1つは「0」つまり「勾配、傾き」が「0」の場合です。これは先に最適化理論で説明した②「非線形計画問題」の「解法」の「簡単な場合」です。つまり微分して「0」になる点を最適解として一義的に求めます。
但し、ディープラーニングの場合、「難しい場合」です。つまり「微分」により一義的に求められないため、前述の通り、「微分の勾配」により徐々に「最適解」に近づく方法です。
これは2つの場合があります。1つは「勾配が-」の場合です。この場合は「最適解」は右にあるため、徐々に「右に移動」します。もう1つは「勾配が+」の場合です。この場合は「最適解」は左にあるため、徐々に「左に移動」します。
これを式で書くと、 となります。ここで(∂E /∂wij)が「微分の勾配、傾き」です。また「ρ」は学習率です。
但し、これで調整できるのは「出力層」つまり「3層目」につながる「w」だけです。では「2層目・1層目」につながる「w」を調整するにはどうすればいいのでしょう。ここで活用されるのが❺「誤差を逆伝搬する合成関数の偏微分法」です。
最初に「合成関数」から説明します。この一例は「誤差、E」と「重み、w」です。つまり「E」は「w」の「合成関数」として次のようにつながっています。すなわち「E」は「z」の関数であり、「z」は「u」の関数であり、「u」は「w」の関数です。
そのため「重み、w」による「合成関数の誤差、E」の偏微分は と表現されます。ここで「∂E /∂w」は(∂E
/∂z) X (∂z /∂u) X (∂u /∂w)と表現され、(∂E /∂z) X (∂z /∂u)を(∂E /∂u)と表現すると、最終的に(∂E
/∂u) X (∂u /∂w)とまとめる事ができます。
次にこれを「2乗誤差」について解いてみると、(∂u /∂w)は となります。尚、(l-1)は(l-1)層を意味する添え字です。また(∂E /∂u)は となります。そのため前述の移動の式は となります。
ここでδiは「出力層」では (1式)となります。同様に「出力層以外」では
(2式)となります。
さてここで留意する事は(2式)からご理解頂ける通り、「l層目のδ」は「1つ前の層」つまり「l層目+1のδ」から導かれる事です。そのため(1式)により「出力層」つまり「3層目のδ」から「2層目のδ」を求める事により「2層目につながるw」を導け、そして「2層目のδ」から「1層目のδ」を求める事により「1層目につながるw」を導く事ができます。これにより「すべての重み、w」を「誤差」を最小化するように調整できます。
お分かり頂ける通り、「誤差をuで微分したδ」を逆伝搬するする事により➊「学習の進捗度を表現する数式」の「u = wx + b」の「重み、w」を、誤差を最小化するように調整する事ができます。尚、これは「バイアス、b」も同様です。これが「誤差逆伝搬法」と呼ばれるものです。十分ご理解頂ければと思います。
では最後に「まとめ」としてここまで説明した事を、イギリスの科学雑誌ネイチャーに2015年に寄稿された ディープラーニングの生みの親である「ヒントン
トロント大学教授」の「ディープラーニングの解説」から説明します。これは3点あります。「1番目と2番目」は「技術のエッセンス」であり、「3番目」は「今後の予測」です。
では1番目から説明します。これは①「ディープラーニングは複数の抽象化レベルにより内部表現を学習する複数の処理層から構成されるコンピュータ的モデルを可能とします」です。
このポイントは❶「複数の抽象化レベル」と❷「内部表現」と❸「複数の処理層」と➍「コンピュータ的モデル」です。但し、いささか理解し難いと思います。そのため「犬の顔の画像認識」を例に意訳して説明します。
まず❶「複数の抽象化レベル」は「犬の顔の輪郭」や「目・鼻・耳・額などの輪郭」や「目の縁・眼球などの細部の形状」や「肌の色や毛並みなどの詳細」などを指しています。つまり「大→中→小」と「犬の顔」を「詳細化するレベル」が「複数の抽象化レベル」という事です。
次に「犬の顔の輪郭」や「肌の色や毛並みなどの詳細」などを❷「内部表現」を呼びます。つまり「犬の顔」は「これらの内部表現の合体されたもの」として「人間」からは見えるという意味です。
この「内部表現」を学習する「1層から3層」までの「ニューラルネットワーク」が❸「複数の処理層」という意味です。これらの「複数の処理層」から構成される「ニューラルネットワーク」が順番に「1層目」で「犬の顔の輪郭」→「2層目」で「目・鼻・耳・額などの輪郭」→「3層目」で「目の縁・眼球などの細部の形状」→「4層目」で「肌の色や毛並みなどの詳細」という「内部表現」を学習します。つまり「ニューラルネットワーク」の「各層」が順番に「大→中→小」と「内部表現」を学習します。
このように「内部表現」を学習する「複数の処理層」として構成される「ニューラルネットワーク」が➍「コンピュータ的モデル」という意味です。これは2つの意味があります。
1つは「コンピュータのソフトウエア」として実現されるという事、もう1つは「ソフトウエア」として実装されますが、それは「アルゴリズム」ではなく「モデル」であるという事です。この理由は「複数の抽象化レベル」という「状態の遷移」を実行するからです。
つまり「1層目」で「犬の顔の輪郭」→「2層目」で「目・鼻・耳・額などの輪郭」→「3層目」で「目の縁・眼球などの細部の形状」→「4層目」で「肌の色や毛並みなどの詳細」という「状態の遷移」を実行するからです。
これが「モデル」という意味です。この事は「原理とは状態を遷移させる仕組み」という「私の定義」からも十分ご理解頂けると思います。そのため「原理の方法論」つまり「モデル」は「ニューラルネットワーク」、それに対して「手順の方法」つまり「アルゴリズム」は「順方向伝搬」と「誤差逆伝搬」となります。
次に2番目は②「ディープラーニングは前の層の表現から各層の表現を計算するために使われる内部パラメータを機械(ディープラーニング)が変更できるように指示する逆誤差伝播法アルゴリズムを使って大きなデータセットに複雑な構造を発見します」です。これは既にご理解頂けると思います。
これを前述の私の説明で言えば、「3層目のδ」から「2層目のδ」を求める事により「2層目につながるw」を導け、そして「2層目のδ」から「1層目のδ」を求める事により「1層目につながるw」を導く事ができます。これによりすべての「重み、w」を「誤差」を「最小化するように調整できます」という事です。
また「この調整を何度も繰り返す事」により、「犬の顔」という「大きなデータセット」に「犬の顔の輪郭」→「目・鼻・耳・額などの輪郭」→「目の縁・眼球などの細部の形状」→「肌の色や毛並みなどの詳細」という「複雑な構造を発見します」という事です。
以上を要約すると、「ディープラーニングの主体」は「複数の抽象化レベル」を実装する「ニューラルネットワーク」という「モデル」である事、もう1つは「複数の抽象化レベル」に複雑な構造を発見するのが「逆誤差伝播法」という「アルゴリズム」である事です。
これは「画像認識」や「言語認識」に依存しない「ディープラーニングの本質」です。もちろんChatGPTもこれに基づいています。そのため「ディープラーニングの本質」として十分ご理解頂ければと思います。
では次にこの本質を更に深掘りして説明します。これは「逆誤差伝播法」です。これが「複数の抽象化レベル」に複雑な構造を発見します。
そのため認識の要となるのは誤差逆伝搬法である事です。これをざっくり言えば、順方向伝搬の様々なアルゴリズムは「入力ベクトル」を運ぶコンベヤのようなものです。その「入力ベクトル」の意味を理解し、それに応じてニューラルネットの膨大な重み、つまりパラメータを調整するのは誤差逆伝搬法である事です。
そして、これが最も重要なポイントですが、「逆誤差伝播法」がどのようにパラメータを調整し、どのようなニューラルネットの役割りを定めるかは 誤差逆伝搬法だけが知っていて、人間には分からないという事です。これがニューラルネットの本質であり、
ChatGPTがどのように言語を生成するのか良く分らないという根本原因である事です。 これが真の「ディープラーニングの本質」です。そのため十分ご理解頂ければと思います。
では後半として「画像と言語の認識」を説明します。これを次に示します。
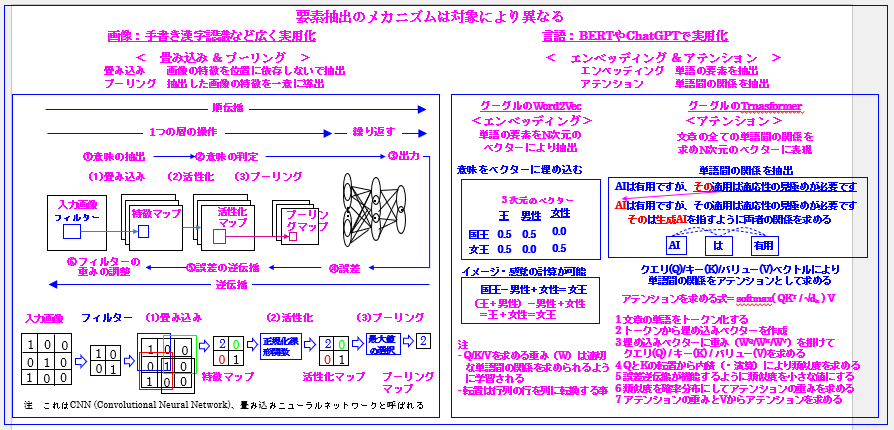
ご覧頂ける通り、「画像と言語の認識のメカニズム」は異なります。「画像」のポイントは「畳み込み」と「プーリング」です。「言語」のポイントは「エンベッディング」と「アテンション」です。
尚、前述の通り、「認識の複数の抽象化レベル」つまり「複数の異なるタイプの要素を抽出する層(モデル)」と「誤差逆伝搬というアルゴリズム」という「ディープラーニングの本質」更に「真のディープラーニングの本質」は不変です。
しかし、個別分野に入ると、この事を忘れ、分野固有の理解に関心が移ってしまい、その結果、「ディープラーニングは理解困難」となりがちですので、「柱」としての「ディープラーニングの本質」と「真のディープラーニングの本質」に基づいてしっかりご理解頂ければと思います。
では最初に「画像」の「要素抽出」から説明します。これは「画像の特徴を位置に依存しないで抽出」する「畳み込み」と「抽出した画像の特徴を一意に導出」する「プーリング」から構成されます。
尚、ここで「画像の特徴を位置に依存しないで抽出」するという意味は「手書きの場合、縦や横に極端に長くなる場合」がありますが、「そのような局所的な位置関係に囚われるの」ではなく「大局的な位置関係から特徴を捉える」という意味です。また「畳み込み」と「プーリング」の間に先に説明した「活性化関数」が適用されます。
これを図に基づいて説明すれば、「入力画像」は「3x3」の「1」または「0」で表現され、次に「2x2」の「フィルター」で「畳み込み」します。つまり最初に左上の入力画像の「2x2」に対して「フィルター」の「2x2」の「値」と掛け合わせ、合計する「1x1+0x0+0x0+1x1=2」という計算をします。これが「特徴マップ」の左上の「2」となります。
以下同様な計算を、フィルターを移動して行い「2x2」の「特徴マップ」を求め、これを先に説明した「活性化関数」の「正規化線形関数」の「z = max(u,
0)」に入力します。この意味は「uの値」が「マイナスならば0」、「プラスならばuの値」となるものです。
そのため「特徴マップの値」は「マイナス」ではないので「特徴マップ」と同じ「値」が出力され、最後に「プーリング」に入力されます。ここでは「マックスプーリング」つまり「最高値」を選択します。その結果、出力は「2」となります。
つまり「3x3」の「入力画像」は「2」と認識されます。この意味は「何等かの画像の断片が存在する」という意味です。以下、これと同様な操作を「100x100」や「1000x1000」などの大きな画像に適用し「画像」を認識します。
次に先に説明した「1x1+0x0+0x0+1x1=2」という計算は前述の①「要素の抽出 → 重み付け和」の「u1=w11x1+w12x2 +w13x3 +b1」と同じである事がご理解頂けると思います。
つまり「w」、「重み」が「フィルター」の「値」であり、「x」が「入力画像」の「値」です。そのため「正解」を与えて「誤差逆伝搬」により「フィルターの値」つまり「w」、「重み」を調整する事により「画像の要素」を抽出します。これに基づいて画像を認識します。以上が「画像認識のメカニズム」です。
では次に「言語認識のメカニズム」を説明します。さてここからがChatGPTにも関係してきます。そのため露払いとしてこれらに関係する事も併せて説明します。
では「言語認識のメカニズム」を説明します。「言語認識の要素抽出」は「要素の抽出」を行う「エンベッディング」と「単語間の要素の抽出」を行う「アテンション」から構成されます。尚、一番最初に「トークン化」がありますが、これはChatGPTで説明します。
「エンベッディング」は「グーグルのWord2Vec」で採用され、「単語の要素」を「N次元のベクトル」にエンベッディング(埋め込み)し、抽出します。
ここで「N次元の各要素」は「要素の断片」を表現します。例を挙げれば、トップページで説明した「国王」は「王=0.5」+「男性=0.5」などです。「国王」は「王=0.5」+「男性=0.5」という「2次元の要素の断片」を保持しますが、これは前述の「u1=w11x1+w12x2 +w13x3 +b1」と同様に求められます。つまり何等かの問題を解かせ、その時の「w」、「重み」が「王=0.5」+「男性=0.5」という「2次元の要素」となります。
次に「アテンション」は文章の全ての単語間の関係を求めN次元のベクトルに表現するものです。これは「グーグルのTransformer」で採用され、そして「Transformer」は現在グーグルのBERTやChatGPTで採用される言語認識、更には画像認識など広範囲に使用されているAIの基本技術となっているものです。
お分かり頂ける通り、Transformerは非常に重要です。これを理解する事はChatGPTの半分を理解したと言っても過言ではありませまん。そのためTransformerのアテンションについて理解し易いように「価値→原理→手順」を順を追って説明します。
では最初に「価値」としてTransformerのアテンションは何ができるのかを説明します。
これは図に示すように「AIは有用ですが、その適用は適応性の見極めが必要です」で言えば、「その」は「AI」を参照できるようにする事です。
ではこのような単語間の関係はどのようなものがあるのでしょう。それをTransformerのアテンション機構はどのように表現するのでしょう。次にこれを先にトップページでは説明したTransformerに基づくグーグルのBERTの例から説明します。次にこれを示します。
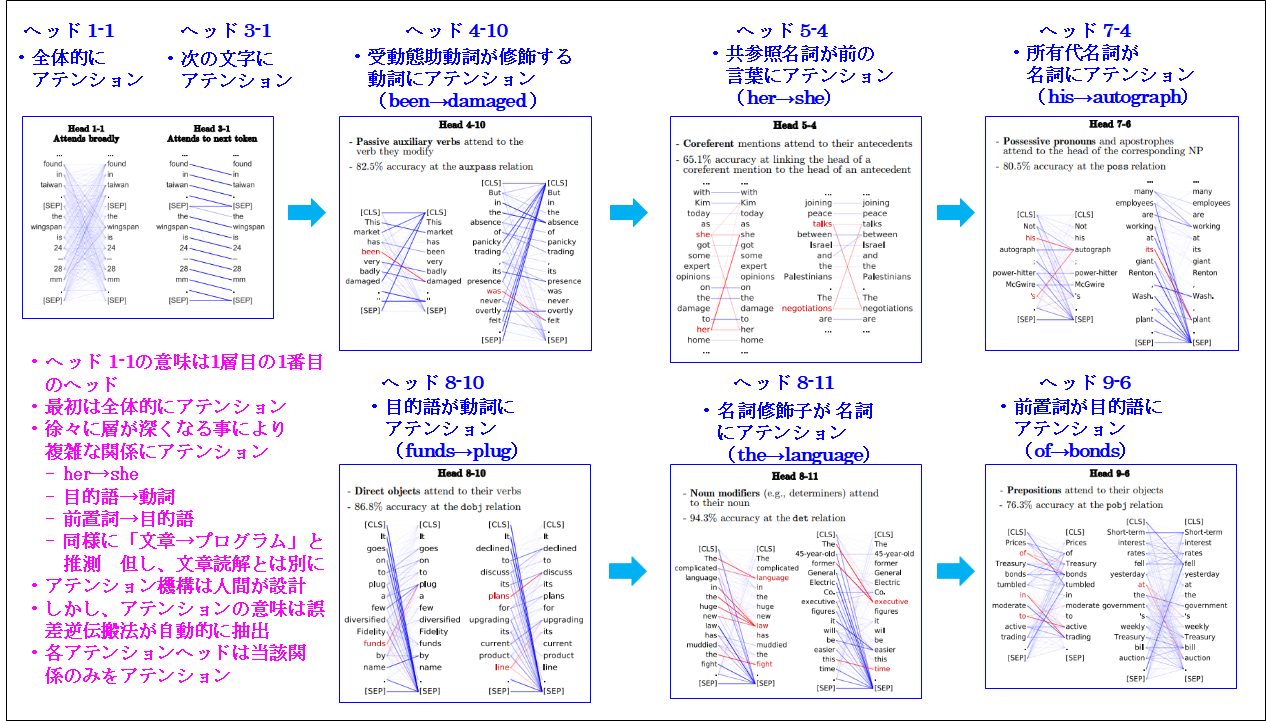
ご覧頂ける通り、これはBERTのアテンションの結果を表示したものです。尚、BERTには文章を読み込むヘッドが何層もあり、また各層にも読み込みヘッドは複数あります。そのためヘッド
1-1の意味は1層目の1番目のヘッドという意味です。
お分かり頂ける通り、最初は「全体的にアテンション」し、徐々に層が深くなる事により「複雑な関係」にアテンションします。
例えば、「ヘッド 4-10」は現在完了形の「has been damaged」の受動態助動詞の「been」と修飾する動詞の「damaged」との関係つまりアテンションします。また「ヘッド
5-4」は「共参照名詞」の「her」が前の「言葉」の「she」にアテンションします。
以下同様に「ヘッド 7-4」は「所有代名詞の「his」が「名詞」の「autograph」ににアテンションし、「ヘッド 8-10」は「目的語」の「funds」が「動詞」の「plug」にアテンションし、「ヘッド
8-11」は「名詞修飾子」の「the」が 「名詞」の「language」にアテンションし、「ヘッド 9-6」は「前置詞」の「of」が「目的語」の「bonds」にアテンションします。
このように精緻に文書の単語間の関係を抽出するのがアテンション機構です。またこの延長上に「文章の単語」から「プログラムの命令」つまり「プログラム」を生成できる事も推察できるのではないかと思います。、
さてここでご理解頂きたい事はアテンション機構は人間が設計しますが、アテンションの意味、つまり単語間の関係は誤差逆伝搬法が自動的に抽出します。
これを視点を変えて言えば、誤差逆伝搬法は各アテンションヘッドが当該関係のみをアテンションするような精緻な仕組み、つまり「専門家」を作り上げるという事です。そのため
「アテンションヘッドの数」だけ「専門家」が作成されるという事です。
これは大規模言語モデルの構造を理解する上で有用な知見となります。これについてはChartGPTで説明しますが、「各ヘッドが役割が一義的に決まっているというニューラルネットの構造」をご記憶頂ければと思います。
このように文章の単語間には様々な関係があります。この情報を抽出する仕組みがアテンション機構であり、その情報の意味を正解データから抽出するのが誤差逆伝搬方法です。ではアテンション機構はどのように単語間の情報を抽出するのでしょう。
では次に「アテンションの原理」を説明します。最初に概要を説明します。アテンション機構はクエリ(Q)/キー(K)/バリュー(V)により単語間の関係の情報をアテンションとして求めます。ここでアテンションを求める式が「softmax(
QKT / √dk ) V」です。
では「アテンションのメカニズムの原理」つまり「状態の遷移」を説明します。これは次の「7つのステップ」つまり「状態の遷移」として求められます。
1 文章の単語をトークン化する
2 トークンから埋め込みベクトルを作成
3 埋め込みベクトルに重み(W)を掛けてクエリ(Q)/キー(K)/バリュー(V)を求める
4 QとKの転置から内積(・演算)により類似度を求める
5 誤差逆伝搬が機能するように類似度を小さな値にする
6 類似度を確率分布にしてアテンションの重みを求める
7 アテンションの重みとVからアテンションを求める
尚、理解を容易にするため次の図に基づいて「アテンションの求め方」を説明します。また「アテンション機構の手順」となる前記のアテンションを求める式(「softmax(
QKT / √dk ) V)も併せて説明します。
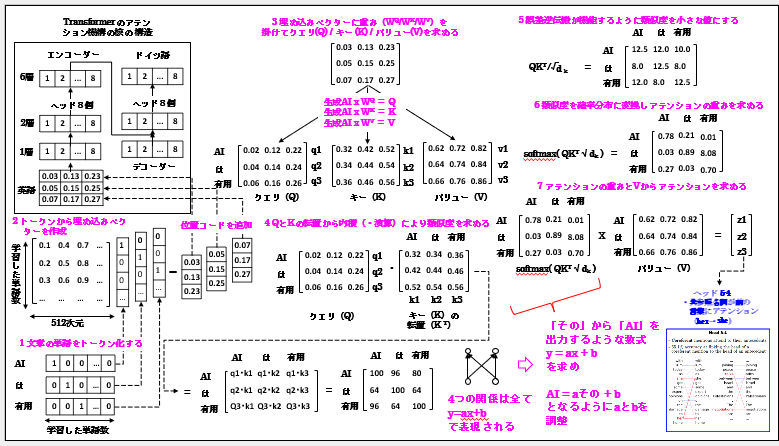
では「1 文章の単語をトークン化する」から説明します。最初に「トークン」から説明します。これは文章の単語の事です。例えば、前述の「AIは有用ですが」で言えば、「AI」、「は」、「有用」、「ですが」が「トークン」です。これをコンピュータで取り扱える「数字のベクトル」に変換する事を「トークン化」と呼びます。
ではこれをどのようにやるのかと言えば、今学習した単語が「1万個」と仮定すると「1万の次元」つまり「セル」を持つベクトルを用意します。次に「この1万個のセル」に順番に学習した単語を割り当てます。
例えば、「AI」は「1番目のセル」、「は」は「2番目のセル」、「有用」は「3番目のセル」と「1万個すべての単語」を「1万個のセル」に割り当てます。
次に入力の文章に「AI」があれば、「1番目のセル」を「1」にし「残り9999個のセル」は「0」にします。同様に「は」は「2番目のセル」を「1」にし「残り9999個のセル」は「0」にします。以下同様に全ての入力文章の単語を「トークン化」していきます。これが「文章の単語をトークン化する」という意味です。
以降、「全ての単語」は「各々1つの数値の集まり」つまり「数値列のベクトル」として取り扱われます。そのため「トークン化された1つの数値の集まり」を「トークンベクトル」と呼びます。
尚、入力の時にこのように単語をトークン化し、次にアテンション機構はこのトークンベクトルに様々なベクトル計算を行いますが、最後にこれらのベクトルを単語に変換する時は入力とは逆に行います。
つまり「1万個のセルを持ったベクトル(logitsと呼ぶ)」を用意し、例えば、出力文字が「日本」であり、それが「10番目のセル」に割り当てられていいるならが、そのセルに最も高い確率の数値を書き込み、それから「日本」を出力します。
お分かり頂ける通り、AIは内部で複雑な計算を実行しますが、入出力のやり方は理解し易いものです。そのため「入力」と「出力」をしっかりご理解頂ければと思います。
では次に「2 トークンから埋め込みベクトルを作成」を説明します。これは前述の「トークンベクトル」を先に「エンベッディング」で説明した「埋め込みベクトル」に変換するものです。尚、以降は全て「ベクトル」つまり「行列」の計算になります。
これは「埋め込みベクトル行列」を用いて行います。このサイズは学習した単語が前述の1万の場合、行数は1万となります。またの次元が512とすると512列となります。そのため「1万行と512列」の「埋め込みベクトル行列」となります。
これに「AI」の「トークンベクトル」つまり「1、0、と0が9999続く」を掛けると図の通り、「0.03、0.13、0.23」となります。尚、これは512行X1列の行列ですが、「残りの509個の数値」は省略してあります。同様に「は」は「0.05、0.15、0.25」、「有用」は「0.07、0.17、0.27」となります。またこれらや以降の数値はすべて任意に決めたものです。
次にこれらの埋め込みベクトルを一度に並列に入力します。但し、単語間の関係を計算する時は1語ずつ計算しますので、図のように埋め込みベクトルが上から「0.03、0.13、0.23」、「0.05、0.15、0.25」、「0.07、0.17、0.27」と積み重ねられた状態となります。
尚、単語の関係を求める時に重要なのが位置情報です。そのため埋め込みベクトルに位置情報のコード化したものを512次元毎に加算します。
では次に「3 埋め込みベクトルに重み(W)を掛けてクエリ(Q) /キー(K) /バリュー(V)を求める」を説明します。さてここからがアテンションの説明になります。
最初に理解を容易にするためにTransformerのアテンション機構の核の構造を説明します。これは2つに分かれます。1つはエンコーダー、もう1つはデコーダーです。
エンコーダーは読み込みのヘッドを8個持ったマルチヘッドが6層に積み上げられています。またデコーダーにも読み込みのヘッドを8個持ったマルチヘッドが6層に積み上げられています。尚、マスクされたヘッドもありますが、省略しています。
Transformerは英語からドイツ語の翻訳をします。そのため英語がエンコーダーに入力され、ドイツ語がデコーダーから出力されます。尚、エンコーダーとデコーダーの役割は異なります。エンコーダーはシナリオライターのようにどのように翻訳するかの筋書きを出力し、デコーダーはその筋書きに基づいて翻訳するという感じです。
例えば、エンコーダの各ヘッドは先に説明したように「been」と「damaged」との関係や「her」と「she」との関係を抽出し、デコーダーに渡します。デコーダーではエンコーダーからの出力を参考にしてドイツ語を生成します。例えば、文章の前半の動詞が過去形ならば、後半の文章の動詞も過去形にするというように翻訳します。
では次に具体的に説明します。図に示すように、埋め込みベクトルに重み(WQ/WK/WV)を掛けてクエリ(Q) / キー (K) / バリュー(V)を求めます。尚、重み(WQ/WK/WV)は適切な単語間の関係を求められるように学習されます。
クエリ(Q) / キー (K) / バリュー(V)は図に示すように全て3行3列の行列となっています。一番上が「AI」に相当し、2番目が「は」に相当し、3番目が「有用」に相当します。尚、単語はまだ続きますが3単語、3行に省略してあります。また列は3次元、3列に省略してあります。尚、ヘッドが8個ありますので、次元は512から 64次元に縮小しています。
では次に「4 QとKの転置から内積(・演算)により類似度を求める」を説明します。 尚、図に示すように転置は行列の行を列に転換する事です。これによりクエリの各行(q1、q2、q3)とキーの各列(k1、k2、k3)の単語間の関係を適切に求められるようになります。尚、内積はベクトルの類似度を求める事ができます。
つまり「AI」が現在の位置、この単語を軸にして「AI」、「は」、「有用」との類似度を内積により求めます。同様に「は」を軸にして「AI」、「は」、「有用」との類似度を内積により求めます。最後に「有用」を軸にして「AI」、「は」、「有用」との類似度を内積により求めます。この結果が右の3行3列の行列になります。尚、数値は任意にきめてありますが、自分との類似度はお大きな数値になるようにしてあります。
では次に「5 誤差逆伝搬が機能するように類似度を小さな値にする」を説明します。既に説明したように、ディープラーニングの肝は「誤差逆伝搬方法」であり「微分」です。微分できないような数値になっては学習ができません。そのため類似度を小さな値にします。具体的にはキーの次元(64)の平方根の8で割ります。
では次に「6 類似度を確率分布にしてアテンションの重みを求める」を説明します。図に示すように類似度は計算結果のままですので、これを0から1の間の確率分布に変換し取り扱い易くします。これを行うのがsoftmax関数です。この結果を「アテンションの重み」と呼びます。これは単語間の関係を示します。大きいほど単語間の関係が強いという事になります。
では最後に「7 アテンションの重みとVからアテンションを求める」を説明します。これは図に示すように「アテンションの重み」とバリューVを掛けてアテンションを求めるものです。
これは図に示すように「アテンションの重み」とバリューVを掛けてアテンションを求めるものです。つまり実際の数値としてはバリューVの数値が参照される事になります。
これは実際の計算結果がないと具体的に示す事はできませんが、冒頭で説明した「その適用」の「その」で言えば、これと「AI」の掛けた数が最も大きな数となり「その」は「AI」を参照するという事になります。その結果、下に示すように様々な単語間の関係を求める事ができるという事になります。
では最後にまとめます。ディープラーニングの全ては「y=ax+b」に要約され、xという入力が与えられた時に出力のyが正解データに近づくように重み「a」とウエイト「b」を誤差逆伝搬法で調整する事です。
そのためここまでの計算を、例えて言えば、「その」から「AI」を出力するように「AI=aその+b」となる「a」と「b」を誤差逆伝搬法で調整し、そのようにした事により、単語間の関係を求められるようになったという事です。ご理解頂ければと思います。
このようにBERTではTransformerを採用し、従来のグーグル検索では英文の「前置詞の意味」を理解できませんでしたが、「前置詞の意味」を理解し、適切に検索できるようになりました。次にこの例を示します。
|
検索文 |
BERT以前 |
BERT以後 |
|
|
2019 brazil traveler to usa need a visa |
you can go to Brazil without a visa .. |
in general, tourists traveling to the United States require valid B-2 visas. |
|
|
「2019年のアメリカへ入国するブラジル人はビザが必要」という検索に対して以前は「あなたはブラジルにビザなしで行ける」という誤った情報を提供していたが、以後は「一般的にアメリカへの旅行客は有効なB-2ビザが必要」という正しい情報を提供 |
|||
|
do estheticians stand a lot at work |
The type of business in which an esthetician works can have an impact on her earnings. |
Speak clearly so listeners can understand. Hold the arm and hand in one position or hold the hand steady while moving .. |
|
|
「エスティティシャンは立ち仕事が多いですか」という質問に対して以前は「エスティティシャンの働く仕事のタイプは収入に大きなインパクトを与える」という誤った情報を提供したが、以後は「クリアに話しなさい、そうすれば受講生は理解できる。動いている時は腕を保ち、手を1つの位置に置くか、手を安定にしなさい」という正しい情報を提供 |
|||
|
Can you get medicine for someone pharmacy |
Getting a prescription filled : MedlinePLus Medical Encyclopedia |
Can a patient have a friend or family member pick up a prescription |
|
|
「あなたは薬局で他の人の薬を受け取る事ができるか」という検索に対して以前は「処方箋の記入方法」という誤った情報を提供していたが、以後は「患者は友達または家族に処方箋を受ける取る事ができるか」という正しい情報を提供 |
|||
|
math practice book for adults |
..Math Workout Resource Book, Grades 6,ages 11-12.. |
Math for Grownups : Re-Learn the Arithmetic you Forget From.. |
|
|
「大人向けの数学の教習本」という検索に対して以前は「11才から12才向けの数学の本」という誤った情報を提供したが、以後は「大人たち向けの数学の本:あなたが忘れたしまった代数学を再学習しましょう」という正しい情報を提供 |
|||
|
Parking on hill with no curb |
When headed uphill at a curb |
For either uphill or downhill parking, there is no curb, |
|
|
「縁石のない丘の道路での駐車」という検索に対して以前は「縁石のある道路を登っている時」という誤った情報を提供していたが、以後は「登り坂または下り坂の駐車であれ、縁石がないならば」という正しい情報を提供 |
|||
|
Search is not a solved problem Even with BERT, we don’t always get it right. If you search for “what state is south of Nebraska,” BERT’s best guess is a community called “South Nebraska.” (If you've got a feeling it's not in Kansas, you're right.) |
|||
|
検索は解決された問題ではない BERTにおいても、我々はいつも上手くやれる訳ではない。もし、「ネブラスカの南にある州は何か」と検索すれば、BERTの最も良い解答は「南ネブラスカ」と呼ばれる地域です。 |
|||
出典 Understanding searches better than ever before
andu Nayak Google Fellow and Vice President, Search Oct 25, 2019
ご覧頂ける通り、「グーグル検索」は、「BERT」により大きく進化しました。「BERT以前」は「前置詞」が正しく認識されないため「誤った情報」を提供していましたが、「BERT以後」は「to」、「at」、「for」、「with」などの「前置詞」を正しく認識し「正しい情報」を提供できるようになりました。
但し、下記の通り、これで「検索は解決された問題」となった訳ではありません。例えば、「ネブラスカの南にある州は何か」と検索すれば、BERTは「南ネブラスカ」と答えます。言うまでもなく、これは誤りです。「南ネブラスカ州」という「州」はアメリカにはありません。
ではこれは何を意味するのかと言えば、BERTは「知識に基づいて答える能力はない」という事です。ここで「知識」は「アメリカの50州の名前と位置の知識」です。これに基づいて答える能力はないという事です。ではこれを解決するにはどうすれば良いのでしょう。そうですね。ChatGPTの何でもかんでも学習させる事です。
では次に「ChatGPT」を説明します。
1.8 CahtGPT
では次に「CahtGPT」を説明します。先に説明したようにBERTは「ネブラスカの南にある州は何か」という質問に答える事はできませんでした。しかし、ChatGPTはご承知の通り、あらゆる質問に答えられ、また要約もアイデア出しも翻訳もでき、更にはプログラムや画像も作成します。但し、真っ当に「嘘」をつきます。つまりハルシネーションを起こします。
ではなぜそのような事が可能なのか、逆に嘘をつくのか、そして今後の進展はどのようなものなのか、これを次の通り、 4つに分けて説明します。
1 ChatGPTの進展と概要
2 GPT-3の内部のメカニズム
3 GPT-3のパラメータの内訳
4 GPT-3の処理の流れ
5 ChatGPTの本質と問題」
を説明します。十分ご理解頂ければと思います。
では最初に「1 ChatGPTの進展と概要」を説明します。これを次に示します。
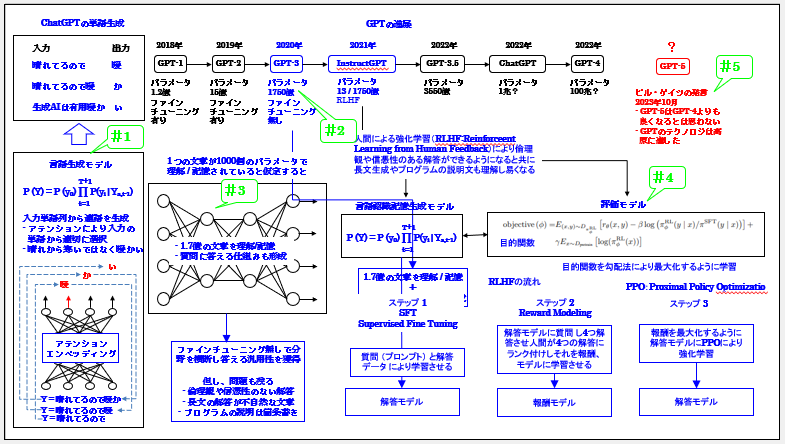
ご覧頂ける通り、ChatGPTは2018年のGPT-1から2022年のChatGPT、そして今年のGPT-4と急速に進展してきました。そのため今後のGPT-5はいつ登場するのかと気になるところですが、10月にビル・ゲイツは以下の通り、発言しました。
- GPT-5はGPT-4よりも良くなるとは思わない
- GPTのテクノロジは高原に達した
尚、言うまでもありませんが、ChatGPTの今日あるのはビル・ゲイツのお陰です。OpenAIのCEOのサム・アルトマンはビル・ゲイツに開発計画を説明し、開発中のChatGPTをデモし、ビル・ゲイツは信頼し、彼、つまりマイクロソフトが1兆円以上の開発資金を提供する事によりChatGPTは誕生しました。
つまりビル・ゲイツはChatGPTの生みの親でもあり、当然ですが、ChatGPTを良く知っています。そして莫大な金を投資しChatGPTはデビューし、世界に大きな衝撃を与え「人類の進歩を根本から変えるのではないか、そして人間の能力を超える汎用人口知能、AGIの登場も近いのではないか」とAIへの期待が高まる中で、なぜこのような水を差すような発言をしたのでしょう。
これには深い理由があります。この事は内部のメカニズムと処理の流れ、そしてChatGPTの本質と問題をご理解頂ければ十分ご理解頂けます。ここではこの事を意識して説明します。
では概要を説明します。これを5つに分けて説明します。
1 一語ずつ生成する
2 膨大な知識を記憶し答える
3 何故巨大化したのか
4 最後は人間が教える
5 ビル・ゲイツの10月の発言
では「1 一語ずつ生成する」から説明します。これは皆様もご理解頂けると思います。ChatGPTは一語ずつ単語を生成します。そして次に生成した単語を元の文章につなげ次の単語を生成します。これは良くご存知と思います。
但し、その一語を生成するために全てのパラメータを使用して計算するという事です。これは簡単な挨拶の時も、長い文章を作成する時も同じです。つまり文章の長短に関わらず、一定の計算ルーチンを全て実行します。これはプログラムの処理として定まった事を実行するという事からご理解頂けると思います。この仕組みは次の構造と処理の流れから説明します。
さて一語ずつ生成する時の素朴な疑問は、最初に解答の文章全体を分かっていて一語ずつ生成するのか、それとも一語ずつ生成しつつ文章全体を生成するのか、どちらかです。これは次に説明します。
では次に「2 膨大な知識を記憶し答える」を説明します。これも直感的にご理解頂けると思います。ChatGPTは事前学習で膨大な文章を読み込んでいます。そして、それらを記憶しそれらの膨大な知識から解答を生成し答えます。この事は直感的にご理解頂けると思います。
さてここで素朴な疑問はそもそも事前学習によりどのように言語を認識し、認識した言語つまり知識はどこに記憶されているのかです。そしてどのようにアクセスするのかです。更に言えば、その知識に基づいてChatGPTは正誤を解答しますが、それは人間のように知識に基づいて考えて答えているのか否かです。
これらは全て構造と処理の流れで説明します。ここでご理解頂きたい事はChatGPTは「生成AI」と呼ばれますが、正確に言えば、「言語認識記憶生成AI」である事です。つまり言語を認識し、その言語から構成される文章を記憶し、解答を生成する事です。この事は容易にご理解頂けると思います。
さて、では記憶するならば、何等かの記憶するための容量は増加するハズです。それは何かです。では次に「3 何故巨大化したのか」を説明します。
これは直感的にご理解頂けると思います。良く言われるパラメータです。これが増加してきている事です。パラメータ数は次のように驚異的に増加しています。
GPT-1(1.2億) → GPT-2(15億)→ GPT-3(1750億)→ GPT-3.5(3550億)→ GPT-4(1兆?)
ご覧頂ける通り、パラメータは指数関数的に増大しています。これにより記憶容量が増え記憶される知識も増え「何でも答えられる」ようになったと言えます。
但し、記憶量という性能が向上しただけなく機能も向上しています。これが事前学習だけでなく個別問題毎にファインチューニングする必要がなくなった事です。また如何なる質問も受け付けられるようになった事です。これがパラメータ数1750億のGPT-3です。
但し、GPT-3は現在のChatGPTのように人間の会話のように流暢に文章を作成する事はできませんでした。そのため会話のお作法を教える必要があります。
では次に「4 最後は人間が教える」を説明します。さてChatGPTは大規模言語モデル( LLM : Large Language MOdel )と呼ばれるように膨大な文章を読み、学習します。
但し、それをそのまま使っても人間のように流暢に話す事はできません。また読み込んだ文章の中には「差別や暴力に関して倫理的に問題のある文章」が含まれており、それをそのまま話しても困ります。やはり倫理的に問題のある事は話さないようにする事が必要です。また信憑性に問題のある発言も控えるべきであり、当然無用なものであってはなりません。
このような視点から、それらを発言しないようにしたのが「人間による強化学習(RLHF:Reinforceent Learning from Human
Feedback)」です。これはChatGPTの前身の「InstructGPT」で行われました。
これにより人間と同じように流暢な発言となり、また倫理観や信憑性があり有用な解答ができるようになると共に長文生成やプログラムの説明文も理解し易くなりました。尚、プログラムの説明文は以降で説明します。
この強化学習は3ステップで行われます。最初のステップではSFT(Supervised Fine Tuning)というファインチューニングを行います。これは質問
(プロンプト) と解答データ を与えて行う一般的なファインチューニングです。尚、これを「解答モデル」と呼びます。
次のステップでは解答モデルに質問し4つ解答させ、人間が4つの解答にランク付けし、それを報酬モデルに学習させます。この目的関数が上図の式です。誤差逆伝搬法の勾配法により目的関数を最大化するように学習させます。
最後のステップでは報酬モデルと解答モデルが連携する形で報酬を最大化するように解答モデルのPPOにより強化学習させます。尚、PPO(Proximal
Policy Optimization)、近接ポリシー最適化は解答モデルが事前学習した内容から強化学習により大幅に更新されるのを防止すると共に最適化を行う手法で強化学習で広く活用されいます。
この3つのステップにより人間と同じように流暢な発言となり、また倫理観や信憑性があり有用な解答ができるようになりました。そしてその後ChatGPTとして登場しました。尚、InstructGPTはGPT-3に基づいていますが、ChatGPTはGPT-3.5に基づいています。
さて膨大な知識を学習し記憶し、会話も人間と同じように流暢になり、何等問題ないと思われますが、ビル・ゲイツは前述の発言をしました。では最後に「5 ビル・ゲイツの10月の発言」を説明します、これを次に再掲します。
- GPT-5はGPT-4よりも良くなるとは思わない
- GPTのテクノロジは高原に達した
ご覧頂ける通り、これは「GPT-5はGPT-4よりも良くなるとは思わない」の通り、明確にChatGPT-5を否定しています。何故なら「GPTのテクノロジは高原に達した」ためです。
という事ですが、さて、このビル・ゲイツの発言にはChatGPTの内部を十分熟知した者だけが知る事実があります。それを一言で言えば、「ChatGPTが嘘をつく事、つまりハルシネーションを根本的に回避できない」という事です。
つまり現在のChatGPTのやり方、技術では嘘をつく事を解決できないという事です。但し、やれる事は全てやり、その極限まで達したという事です。これが「GPTのテクノロジは高原に達した」という意味です。
では嘘を回避できないならば、何にChatGPTを使えば良いのでしょう。これがマイクロソフトのCopilotです。つまりプログラム作成のGitHub
Copilotやエクセルやパワポなどの365 Copilotなどの「定型業務の自動化」です。これは「定型業務」ですので「決まり切った事」をするだけであり、嘘は発生しません。
尚、プログラム作成は「定型業務の自動化ではない」と感じるかも知れませんが、そうではありません。先にTransformerの単語間の関係を抽出するのがアテンションで説明したように「文章の単語」から「プログラムの命令」への変換は「定型業務の自動化」と同様に行う事が出来ます。
お分かり頂ける通り、ChatGPTの嘘をつく事、ハルシネーションは深刻な問題です。そのため適用するには「定型業務の自動化」の通り、適用先を完全に理解し「嘘を発生しない事」を完璧に確認する事が必要です。そのために今後マイクロソフトが行うのが以下です。
日本マイクロソフトが生成AI活用で500事業創出へ、100社を無償支援
これを来年の2024の1月下旬から開始します。この目的はご理解頂けると思います。適用先を100%理解する事です。そのためマイクロソフトにとっては「勉強」のため「無償支援」という事になります。これにより安全に使う事ができます。
では概要を説明しましたので、次に「2 GPT-3の内部のメカニズム」を説明します。これをGPT-3を例に説明します。最初に内部のメカニズムを説明し、次に処理の流れを説明します。これが勘所となるものです。しっかりご理解頂ければと思います。では内部のメカニズムから説明します。これを次に示します。
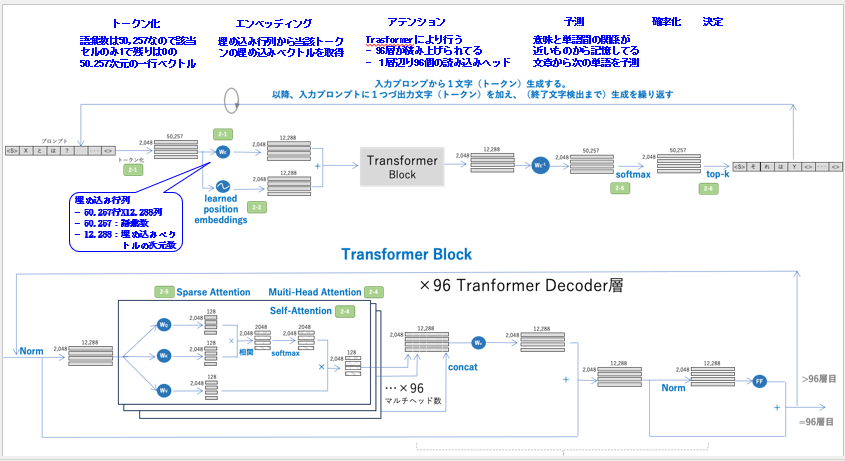
ご覧頂ける通り、内部のメカニズム、つまり処理の流れは以下の7つのステップから構成されます。
1 トークン化
2 エンベッディング
3 アテンション
4 アテンションの強弱化
5 予測
6 確率化
7 決定
8 誤差逆伝搬/出力
では最初に「1 トークン化」から説明します。GPT-3の学習、理解した語彙数は50,257です。そのため該当セルのみ1で残りは0の50.257次元の一行ベクトルとなります。これにより単語が「数値」となりますのでニューラルネットのGPT-3で計算できるようになります。
例えば、「関」という単語が50,257の語彙の3番目ならば、次のように3番目のセルが1、その他の50,256のセルは全て0の50,257次元の一行ベクトルとなります
「関」をトークン化した50,257次元のベクトル
[0、0、1、0・・・、0]
関は3番目のセルのため「1」
他は1番目から最後の50,257番目のセルまで全て「0」
次にGPT-3は一度に2,048個の単語、つまりトークンを読み込みます。つまり最大2,048トークンが並列に入力されます。但し、処理は「1トークン」毎に行われます。つまり順番に行われますので、図のように縦にトークンが積まれた形になります。
尚、読み込みのアテンションヘッドは1層当たり、96個あります。これらが並列に処理をしますが、1つのヘッドは1トークンずつ処理します。そのためヘッドでの処理は順番に行われますので、2,048個のトークンが積まれた形、つまり2,048行となり1行ずつ処理されるという事になります。
そして1トークンは50,257次元です。そのため行列で表現すると「2,048行x50,257列」となります。これが入力の行列となります。
では次に「2 エンベッディング」を説明します。エンベッディングは「埋め込み行列」から当該トークンの「埋め込みベクトル」を生成します。
さてここからは誤差逆伝搬法が適用されます。そのため説明は単にメカニズムを説明するのではなく、誤差逆伝搬法によりどのように重みが調整されるのかを説明する事が必要となりますが、それは次の「ChatGPTの処理の流れ」で説明します。ここではメカニズムを静的に主に構造に焦点を当てて説明します。
最初に「埋め込み行列のサイズ」から説明します。このサイズは「50,257行x12,288列」となります。理由は語彙数の50,257個のトークンが全て埋め込みの次元の12,288個の数値を持つためです。
次にこの埋め込み行列から当該トークンの「1行x50,257列」の埋め込みベクトルを生成するには両者を掛け合わせる事です。つまり「1行x50,257列」x「50,257行x12,288列」=「1行x12,288列」です。その結果、「1行x12,288列」の埋め込みベクトルを生成する事ができます。
実際には1トークンではなくなく最大2,048の入力トークンが考えられますので図の通り、「2,048行x50,257列」x「50,257行x12,288列」=「2,048行x12,288列」となります。尚、ここで覚えて頂きたいのは行列の掛け算です。これは「2行x3列」x「3行x2列」=「2行x2列」のの通り、前の行列の「行(2)」と後ろの行列の「列(2)」が行列の「行(2)x列(2)」つまり「2行x2列」となります。
では次に「3 アテンション」を説明します。これは先に説明したTrasformerにより行います。GPT-3では先に説明したように一層当たり96個の読み込みヘッドがあります。また総数は96あります。つまり一層96個の読み込みヘッドが96層積み重ねられています。
アテンションは先に説明したようにクエリ(Q)/キー(K)/バリュー(V)により計算し、ソフトマックスで確率表現します。一層当たり96個の読み込みヘッドがありますので12,288の次元は96分割され1ヘッド当たり「128次元」となります。
そのためクエリ(Q)/キー(K)/バリュー(V)を求める重み行列WQ/WK/WVの行列のサイズは「12,288行x128列」となります。これから以下の通り、入力行列「2,048行x12,288列」からクエリ(Q)/キー(K)/バリュー(V)を求めます。
入力「2,048行x12,288列」xWQ「12,288行x128列」=「2,048行x128列」 クエリ(Q)
入力「2,048行x12,288列」xWK「12,288行x128列」=「2,048行x128列」 キー(K)
入力「2,048行x12,288列」xWV「12,288行x128列」=「2,048行x128列」 バリュー(V)
次にクエリ(Q)とキー(K)の転置から類似度を求めます。
クエリ(Q)「2,048行x128列」 xキー(K)の転置「128行x2,048列」=類似度「2,048行x2,048列」
また類似度を小さくしソフトマックスにより「アテンションの重み」を求め「アテンションの重み」とバリュー(V)からアテンションを求めます。
「アテンションの重み」「2,048行x2,048列」 xバリュー(V)「2,048行x128列」=アテンション「2,048行x128列」
次に96個のアテンションヘッドのアテンションを連結します。
アテンション「2,048行x128列」を96個連結=「2,048行x50,257列」
出力重み行列を通し正規化し、フィードフォワード(FF)で「4 アテンションの強弱化」を行います。具体的には、トークンの関係、結び付きが強いものは更に強めます。例えば、2つのトークンで1つの単語を形成するものは両者の結び付きを更に強めます。逆に、同一の種類のトークンの結び付きは弱めます。例えば、AprilとMayなどです。
その後出力を次のTransformer層に送り、同様な処理を96回行い、終わると 「5 予測」でフィードフォワード重み行列により予測し、「6 確率化」でソフトマックスにより予測確率を求め、「7 決定」でtop-kにより決定し、「8 誤差逆伝搬/出力」で学習の時は誤差逆伝搬法により重み行列を調整、または実行時は予測語を出力します。
以上、GPT-3の内部メカニズムを説明しました。但し、率直に言って、これでは肝心要の事は全く分かりません。言うまでもなく、アテンションは単語間の関係を抽出するものです。しかし、求められているのは次の単語の確率です。そのために必要なのは確率です。しかし、確率は全く導かれていません。アテンションで導いているのは単語間の関係です。確率ではありません。ではこれは一体全体どうなっているのでしょう。
また皆様も実感していると思いますが、確率よりも、ChatGPTは学習した膨大な情報に基づいて解答しているように見えます。つまり確率ではなく記憶している情報から予測しているように見えます。すなわち「確率」か「記憶」か、どちらに基づいて予測、解答しているのかです。更に言えば、もし記憶から解答しているならば、それはどこに記憶されているのでしょう。またどのようにアクセスするのでしょう。
更に根本的に一層当たり96ヘッドを96層積み重ねた巨大なニューラルネットにした理由は何でしょう。また埋め込みの次元を12,288にした理由は何でしょう。実際、12,288次元には何が入っているのでしょう。そして結果として、1750億のパラメータとなっていますが、それらは前記のメカニズムのどこにあるのでしょう。
これらは「4 GPT-3の処理の流れ」で説明します。その前に説明を分かり易くするために
1750億のパラメータは前記のメカニズムのどこにあるのかを説明します。
では次に「3 GPT-3のパラメータの内訳」を説明します。
最初にパラメータ、つまり「重み行列」はいくつあるかを説明し、次にそれに基づいて1750億を導きます。尚、メインのパラメータのみに焦点を当てて説明します。これにより1750億の99.7%の1745億を導く事ができます。最初に重み行列は次の通り、3種類あります。
1 埋め込み行列WE
2 クエリ/キー/バリュー重み行列WQ/QK/WVとアテンション出力重み行列WOx96ヘッドx96層
3 フィードフォワードのFFのW1とW2x96層
FF(x)=max(0,xW1+b1)W2+b2
ここでは重みWのみを求めます。そのためb1とb2は省きます。最初に 埋め込み行列WEのパラメータ数を求めます。これは既に説明した通り、以下となります。
WE=「50,257行x12,288列」=617,558,016
次にクエリ/キー/バリュー重み行列WQ/QK/WVは既に説明した通り、以下となります。
WQ/QK/WVのサイズ=「12,288行x128列」
これが WQ/QK/WVと3個あるのでx3
WQ/QK/WVのパラメータの数=3x「12,288行x128列」
これが一層当たり96ヘッドあるのでx96
WQ/QK/WVの一層当たりのパラメータの数=3x「12,288行x128列」x96=3x12,2882
アテンション出力重み行列WOのパラメータの数=12,2882
そのため一層当たりのWQ/QK/WVとWOのパラメータの合計数=4x12,2882
これが96層あるのでx96
∴ 一層当たりのWQ/QK/WVとWOのパラメータの合計数=4x12,2882x96=57,982,058,496
次にフィードフォワードのFFは埋め込みの次元12,288を4倍に拡大し、また縮小します。
そのためW1とW2の一層当たりのパラメータの合計数=2(4x12,2882)=8x12,2882
これも96層あるのでx96
∴ 一層当たりのW1とW2のパラメータの合計数=8x12,2882x96=115,964,116,992
合計=617,558,016+57,982,058,496+115,964,116,992=174,563,733,504
ご覧頂ける通り、1750億の99.7%の1745億のパラメータ数を導く事ができました。これを簡略化すると次の通りです。
合計=埋め込み行列の6億(0.3%)+アテンションの580億(33.1%)+フィードフォワードの1160億(66.3%)=1746億(99.7%)
お分かり頂ける通り、1750億の33.1%の580億のパラメータがアテンションにあります。また66.3%の1160億のパラメータがフィードフォワードにあります。ではこの意味は何でしょう。次にこれを示します。
1750億のパラメータの意味=重み行列(トークン数x埋め込みベクトルの次元)+アテンション(4x埋め込みベクトルの次元2x96ヘッドx96層)+フィードフォワード(8x埋め込みベクトルの次元2x96層)
お分かり頂ける通り、「埋め込みベクトルの次元」と「ヘッド数とヘッド層」がパラメータ数の2大要因です。つまりパラメータ数を増やすには埋め込みベクトルの次元とヘッド数を増やす事が必要です。これは以降の説明の勘所となりますので十分ご理解頂ければと思います。
では次に「4 GPT-3の処理の流れ」を説明します。さてここでは先に説明した次の疑問に最初に答え、次にこれらをまとめる形で処理の流れを説明します。これにより頭のモヤモヤを解消し処理の流れをスーとご理解頂けます。
1 ヘッド数を増やす目的と影響
2 埋め込みベクトルの次元には何が入ってるのか
3 単語間の関係が何故確率になるのか
4 単語はどこに記憶されるのか
5 記憶された単語にどうアクセスするのか
では1 ヘッド数を増やす目的と影響」から説明します。ヘッド数を増やす目的は先に説明したBERTからご理解頂けると思います。単語間の関係を様々な視点から抽出する事です。但し、BERTのヘッド数はLargeで一層当たり16ヘッドの24層のため384ヘッドですが、GPT-3は96x96で9,216です。さすがに単語の意味としてこれは多すぎます。
ではなぜこのように多くしたのでしょう。これは2つの目的があると考えています。
1つはプログラムなどの新たなトークンを扱うためです。もう1つはズバリ言って、パラメータの数を大きくするためと考えています。
つまりヘッド数を大きくする影響として自然に次元を大きくせざるを得ないからです。何故なら、新たなヘッドで抽出した特徴は埋め込みの次元に組み込まれなければならないからです。
では次に「2 埋め込みベクトルの次元には何が入ってるのか」を説明します。尚、あらかじめ説明すると、ここからは私の推測です。但し、根拠のないものではなく事実に基づく合理的、論理的な推測とご理解頂ければと思います。この事は以降の説明から十分ご理解頂けます。
最初に結論から言えば、GPT-3の埋め込みベクトルの次元が12,288となった最大の理由は
ヘッド数が前記の通り、9,216になったためと考えています。
尚、GPT-2は一層当たり12ヘッドの48層で576ヘッドですので、GPT-3の9,216ヘッドは
大幅に増加しています。その結果、GPT-2の埋め込みベクトルは1600次元ですが、GPT-3は12,288次元になったと考えています。
何故ならば、先に説明したように、ヘッドが読み込んだ単語間の特徴は埋め込みベクトルの次元に含まれていなければならないからです。
そのためGPT-3の埋め込みベクトルの12,288次元の中で9,216次元ヘッドの抽出する次元、つまり単語間の関係がBERTで説明した「sheとher」のような関係で含まれていると考えています。
ではこの効果は何でしょう。これは2つあると考えています。1つは次の単語を予測する確率として使える事、もう1つは読み込んだ大量の文書を記憶する事と考えています。つまり確率と記憶を同時に行う事です。
最初に確率から説明します。では次に「3 単語間の関係が何故確率になるのか」を説明します。これをご理解頂く鍵は2つあります。1つはGPT-3の次の単語を予測する目的関数、もう1つは行列の掛け算です。最初にGPT-3の次の単語を予測する目的関数を説明します。これを次に示します。
P(x)=softmax(hnWET)
- P(x):次の単語を予測する目的関数
- x:入力単語列
- hn:Transformerの出力ベクトル 「2,048行x12,288列」
- WET:埋め込みベクトルの転置 「12,288行x50,257列」
お分かり頂ける通り、hnWETのポイントは行列同士の内積である事です。そのため重要なのが内積のポイントです。これは図に示すように、同じ行列の内積は1または大きな数になりますが、異なる行列は0または小さな数になる事です。
さて、ここが勘所ですが、もしhnつまりTransformerの出力ベクトルが50,257個あるトークンの或る埋め込みベクトルと同じならば、それは1となり、他は全て0になる事です。
ここで1は予測するトークンの確率が最も高い事を示し、0は予測する確率が最も低い事を示します。そのため1となったトークンが次の予測するトークンとなります。
さて、このポイントはTransformerの出力ベクトルが50,127個の語彙の埋め込みベクトルの1つと一致する事ですが、そのような事は可能なのでしょうか。
それは可能です。正にそれを可能とするように一致するように調整するのが学習時の誤差逆伝搬法です。これにより一致できたから正解を出力できるようになったという事です。
では実際、何が一致したのでしょう。それは「単語間の関係」です。これが一致したから次の単語を予測できるという事です。次にこの関係を示します。尚、これが最も重要な勘所です。十分ご理解頂ければと思います。
前提
1 次元には「天候」がある
2 ヘッドには「天候を調べるもの」がある
3 50,127個の語彙の埋め込みベクトルの「暖かい」の「天候の次元」には「天候と暖かいの関係を示す数値1」がある
4 天候を調べるヘッドのWQ/WK/WVの重み行列には過去に学習した内容から「暖かいと晴れとの関係を示す数値0.9」がある
例
入力:今日は晴れなので
1 天候を調べるヘッドは「晴れ」から重み行列の「暖かいと晴れとの関係を示す数値0.9」と「晴れの数値1」を掛けて「天候の次元を0.9」にセットする
2 Transformerの出力ベクトルの「天候の次元」には「暖かいと晴れとの関係を示す数値0.9」が入ってる
3 50,127個の語彙の埋め込みベクトルの「暖かい」の次元には「暖かいと晴れとの関係を示す数値1」が「天候の次元」にある
4 Transformerの出力ベクトルと暖かいのベクトルの「天候の次元」の内積は「0.9x1=0.9」となる。しかし、それ以外は全て「0」。
5 そのため「暖かい」の「確率」は「0.9」となり選択されるが、残り50,256のベクトルは「天候の次元」が「0」つまり「確率」は「0」のため選択されない。
6 その結果、「今日は晴れなので」の入力後に「暖かい」が出力される
以上から、「単語間の関係」から「確率」が導かれる事を十分ご理解頂けたと思います。これが最も重要な勘所ですの十分ご理解頂ければと思います。
さて、前記の説明には『天候を調べるヘッドのWQ/WK/WVの重み行列には過去に学習した内容から「暖かいと晴れとの関係を示す数値0.9」がある』の通り、学習した「記憶」が関連しています。そのため次に「記憶」との関係を説明します。
では次に「4 単語はどこに記憶されるのか」を説明します。これは既にご理解頂けると思います。WQ/WK/WVの重み行列に記憶されています。但し、直接その単語を記憶するのではなく他の単語の関係から芋ずる式に記憶されています。またその記憶は12,288次元の全ての次元を記憶するのではなく当該関係の次元のみ記憶されています。これも前述の説明から容易にご理解頂けると思います。
以上から、アテンションのメカニズムにより「確率」と「記憶」が同時に為されている事をご理解頂けると思います。
では次に「5 記憶された単語にどうアクセスするのか」を説明します。これも既にご理解頂けると思います。アテンション→softmax(hnWET)による予測という形で全て計算によりアクセスされます。この事も既に十分ご理解頂けると思います。
では最後にこれらをまとめる形で処理の流れを説明します。次にこれを示します。
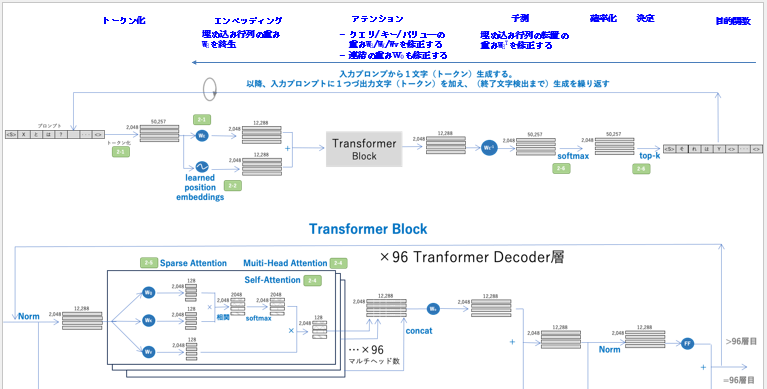
ご覧頂ける通り、学習時の誤差逆伝搬法の流れを説明しています。この目的は前述の説明が成り立つように全ての重みが誤差逆伝搬法により調整されるという事です。
つまりGPT-3/ChatGPT/ニューラルネットの「主役」は「誤差逆伝搬法」であるという事です。例えて言えば、次の通りです。
順方向伝搬 :ベクトルという荷物を運ぶベルトコンベア
誤差逆伝搬法 :荷物の中身のベクトルに意味を与えニューラルネットに命を吹き込むもの
ご覧頂ける通り、「順方向伝搬」は「ベクトルという荷物を運ぶベルトコンベア」であり、
「誤差逆伝搬法」は「荷物の中身のベクトルに意味を与えニューラルネットに命を吹き込むもの」です。この事を十分ご理解頂ければと思います。
では最後に「5 ChatGPTの本質と問題」を説明します。さてここまでの説明からChatGPTの本質を十分ご理解頂けたと思います。これを一言で言えば、次の通りです。
ChatGPTの本質:文章の意味と関係を徹底的に調べて記憶し、それに基づいて次の単語を予測
お分かり頂ける通り、「ChatGPTの本質」は「文章の意味と関係を徹底的に調べて記憶し、それに基づいて次の単語を予測する事」です。この事は今までの説明から十分ご理解頂けると思います。
ではこの問題は何でしょう。それはある根本的な事を忘れている事です。それは「人間の思考」です。言うまでもなく、如何なる文章も人間が理解する事を前提にしています。そのため本当に文章を理解するには「人間の思考」というものを理解していなければなりません。しかし、言うまでもなく、ChatGPTは理解していません。
ではこれから生まれる問題は何でしょう。それは「真偽の判断」であり、そして普遍的勉強法の「価値→原理→手順」の判断です。これができないためChatGPTは嘘をつく、つまりハルミネーションを起こします。
さて、「真偽の判断」は直感的にご理解頂けると思います。しかし、普遍的勉強法の「価値→原理→手順」はトップページで説明した「日本国憲法」や「解決の思考力の根拠」で説明した9つの例の通り、なかなか気がつかないと思います。そのため更に深掘りして説明します。
結論から言えば、如何なる文章そして人間の会話にも「価値→原理→手順」は存在するという事です。これを冒頭で説明した次の文章の「価値→原理→手順」から説明します。
AIは有用ですが、その適用は適応性の見極めが必要です
- 価値:AIは有用
- 原理:適応性の見極め
- 手順:適用できる
お分かり頂ける通り、この文章の価値は「AIは有用」であり、原理は「適応性の見極め」であり、手順は「適用する」です。このように如何なる文章にも「価値→原理→手順」は存在します。
つまり文章には「それぞれのまとまり毎」に「価値/原理/手順」という「役割」があります。そして、人間はその事を前提として文章を理解します。何故なら、解決の思考力の根拠で説明したように人間はそのように思考するからです。
但し、言うまでもありませんが、「思い重視」そして「手順重視」の方は「AIの波に乗ろう」という「思い重視」でスグ「適用する」という「手順重視」と走りがちですが、それが誤りである事は明らかです。
しかし、ChatGPTはどんなに文章を読んでもこの事が分かりません。これを例えて言えば、ChatGPTはプログラムを作成しますが、だからと言って、プログラムを実行するコンピュータの原理を理解していないのと同じです。
プログラムにはコンピュータの原理に関するようなものは何も現れていません。これと同様に文章には人間の思考に関するものは何も現れていません。それを暗黙の内に理解するのは人間だけです。
さて、このように理解してくると、人間の「価値→原理→手順」という思考を理解するAIが必要となってきますが、これは思考するAIで説明します。
ここでは更にもう1つの問題を説明します。それは要約です。これをOpenAIは次のようにChatGPTが行うように設計しています。
推論時に、モデルは最初に本の小さなセクションを要約し、次にこれらの要約を再帰的に要約して、本全体の要約を生成します。当社の人間のラベル付け担当者は、書籍全体を読んでいないにもかかわらず、モデルを迅速に監督し、評価することができます。
お分かり頂ける通り、これは要約というものを全く理解していません。要約とは「価値と原理」です。故に、日本国憲法では「価値と原理」が「前文」に記述されています。またすべての欧米の論文の「Abstract」、「抽象化つまり要約」は「価値と原理」が説明されています。この事は自明です。
にも関わらず、このような安直なやり方をしています。これは明らかに誤りです。ChatGPTは行列/確率/微分の数学のみを使って計算の仕組により文章の意味と関係を徹底的に調べ、記憶する事を実現しましたが、要約は全くいい加減です。これが問題です。
逆に言えば、これもChatGPTを超えるポイントであるという事です。ではなぜその事に私は気がつくのかといえば、「価値→原理→手順」という人間の思考思考を理解しているからです。これが正に「思考するAI」を生み出した原点です。この事を十分ご理解頂ければと思います
では次に「思考するAI」を説明します。
1.9 思考するAI
では「思考するAI」を説明します。「思考するAI」を一言で言えば、「思考の真理」の「解決の思考力」の「価値→原理→手順」を学習し、「文書」を正しく要約し、「問題」を「知識」に基づいて「価値→原理→手順」と解く事ができるAIです。
これは現在の生成AIの問題を解決すると共に「永続的に進化できるAI」です。最初に特徴と構成を説明し、次に具体的に説明します。では特徴から説明します。これは3点です。
1つは生成AIは言語を理解していても、「学問の知識」を理解していないため誤った解答をしますが、「思考するAI」は「学問の知識」に基づいて正しく解答するため「嘘をつく事」、つまり「ハルシネーション」を完全に防止します。
2つ目は生成AIは学習データから順方向と逆方向のメカニズムにより内部に作成されたアルゴリズムにより解答を導くため、どのようにして導いたのかが不明ですが、「思考するAI」は「知識」に基いて人間と同じく「価値→原理→手順」と解答するため「人間と一体感のあるAI」です。
3つ目は生成AIの学習データはまもなく枯渇し進歩が止まりますが、「思考するAI」は「知識」を継続的に追加できるため人間の進歩と共に永続的に進化します。
お分かり頂ける通り、特徴は「嘘をつかない」、「人間と同じ問題の解き方」、「永続的な進化」です。これにより現在の生成AIの「嘘をつく」や「人間と異なる問題の解き方」という問題を解決すると共に将来への進化も保証します。これが「思考するAIの特徴」です。
次に構成は「知識を管理する記号系」と「知識に基づいて問題を解くベクター系」の2つから構成されます。前者の「記号系」が「問題を解く知識」を「価値→原理→手順」として管理します。「問題を解く知識」は人間が作成し「記号系」に登録します。後者の「ベクター系」は従来の生成AIをファインチューニングし「文章を正しく要約」し、「知識」に基いて「問題」を「価値→原理→手順」と正しく解きます。
では次に具体的に説明します。最初に現在の生成AIの問題を分析し、次に解決策の検討を行い、これを踏まえて「思考するAI」の「構成と学習の概要」と「問題を解かせる時の学習」を説明します。これらを全て「価値→原理→手順」に基く「普遍的勉強法」により説明します。そのため容易にご理解頂けます。
では「生成AIの問題の分析と解決策の検討」を説明します。これを次の図に基づいて説明します。
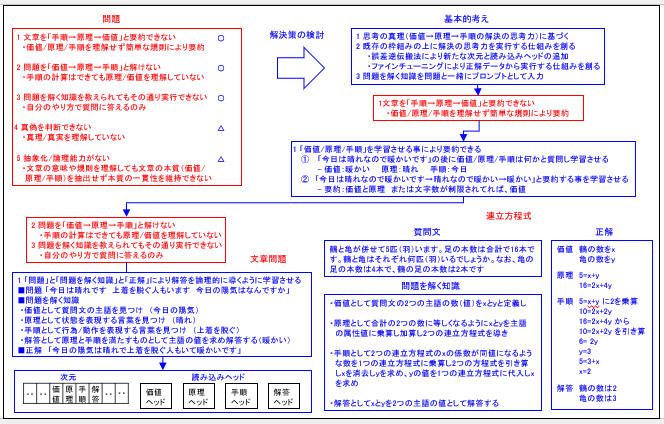
ご覧頂ける通り、現在の生成AIの問題は5点と考えています。これを抜粋して次に示します。
1 文章を「手順→原理→価値」と要約できない
・価値/原理/手順を理解せず簡単な規則により要約
2 問題を「価値→原理→手順」と解けない
・手順の計算はできても原理/価値を理解していない
3 問題を解く知識を教えられてもその通り実行できない
・自分のやり方で質問に答えるのみ
4 真偽を判断できない
・真理/真実を理解していない
5 抽象化/論理能力がない
・文章の意味や規則を理解しても文章の本質(価値/原理/手順)を抽出せず本質の一貫性を維持できない
では最初に「1 文章を「手順→原理→価値」と要約できない」から説明します。最初に現在のChatGPTの要約状況を説明すれば、先に説明したように、以下の通りです。
推論時に、モデルは最初に本の小さなセクションを要約し、次にこれらの要約を再帰的に要約して、本全体の要約を生成します。当社の人間のラベル付け担当者は、書籍全体を読んでいないにもかかわらず、モデルを迅速に監督し、評価することができます。
ご覧頂ける通り、「簡単な規則」により要約しているだけです。これは「正しい要約」ではありません。この根本原因はChatGPTは文章の「言葉の意味」や「品詞」や「構文」を理解しても意味の本質の「価値→原理→手順」を理解していないためです。
例えば、ChatGPTに「日本国憲法とは何」と質問した事があります。解答は「どこにでもある一般的な説明」でしたので、再度「日本国憲法とは何」と手短に質問すると、「憲法の前文の宣言」と「条文の最初の幾つか」を答えてきました。
お分かり頂ける通り、これは要約ではありません。既に「日本国憲法」で説明したように日本国憲法には「国政と外交」の「価値→原理→手順」が明確に定められています。次にこれを再掲します。
■国政
価値:国民主権
原理:その福利は国民がこれを享受する
手順:憲法第13条の個人の尊重
■外交
価値:恒久の平和
原理:他国を無視してはならない
手順:憲法第9条の戦争の放棄
ご覧頂ける通り、「国政と外交」の「価値→原理→手順」が明確に定められています。そのため「国政と外交の価値と原理」を答えるべきですが、ChatGPTはこのように要約できません。この原因は先に説明したようChatGPT/LLMは「言葉の意味」や「品詞」や「構文」を理解しても「文章の本質」の「価値→原理→手順」を理解していないためです。
次に「2 問題を「価値→原理→手順」と解けない」は「価値→原理→手順」の視点から表現したものです。先に説明したようにChatGPTは「価値→原理→手順」という事を全く理解していません。
但し、ChatGPTは「質問」に答えます。では、これは「価値→原理→手順」の「何に相当する」のでしょう。推察できると思います。「手順」です。「ChatGPTの取り扱うもの」は全て「手順」つまり「具象化されたもの」です。
すなわち「文章」という「具象化されたもの」が「ChatGPTの取り扱うもの全て」です。それが「ChatGPTの理解しているもの」であり、「それ以外の事」は何一つ知りません。そのため「手順の計算はできても原理/価値を理解していない」という事になります。
しかし、それでも質問に答えたり、計算し解答を出力します。この理由は「価値→原理→手順」も最後は「手順の実行」という事になるためです。そのため「手順」の本質である「具体化されたもの」として意味の一貫性のある受け答えはできます。
例えば、「太陽は東から登る」という事を学習していれば、「太陽は西から登る」という事に対しては「正否の判断」をできます。そのため「人間と同じ」ように「考えてやっているのか」と言えば、そうではありません。
既に説明したように「過去の文章」を手掛かりに「入力ベクトル」を「出力ベクトル」に変換してる」というのがChatGPTのやっている事です。そこには「価値→原理→手順」というものは何もありません。
つまり文章を読み「単語の意味」と「単語間の関係」更に「品詞」や「構文」を学んでも、「価値/原理/手順」という「文章の本質」を理解していないためです。すなわち「それらの具体化されたもの」の「価値/原理/手順」という「文章での役割り」を「抽出しない」ためです。これが根本的欠陥です。
更にもう1つの根本的欠陥が「3 問題を解く知識を教えられてもその通り実行できない事」です。最初にこの意味から説明します。
既にここまでの説明からご理解頂けると思いますが、ChatGPTは「やり方」は学習していません。ChatGPTは「解答」を与えられ、それに一致するようにパラメータを調整します。つまり「ABC」という単語列 が与えられば、「正解」の「D」という単語を出力するようにパラメータを調整します。
しかし、「ABC」という単語列 が与えらたら「正解」の「D」を「こういうやり方」で「求めなさい」と指示されてもできません。何故なら、それは学習していないからです。あくまでも学習するのは「ABC」なら「D」を出力する事を自分のやり方で学習しているだけです。
そして、その「やり方」はChaGPTのみが「知ってるやり方」です。つまりChatGPTは「自分のやり方で質問に答えるのみ」です。それを「異なるやり方」で「求めなさい」と指示されても不可能です。これがChatGPTの根本的欠陥です。
次に「4 真偽を判断できない」は容易にご理解頂けると思います。ChatGPTは「真偽の判断」はできません。但し、先に説明したように、「太陽は東から登る」という事を学習していれば、「太陽は西から登る」という事に対しては「正否の判断」をできます。
しかし、「太陽は東から登る」という事の「真偽の判断」はできません。この理由は「真理/真実」を理解していないためです。先に説明したように「ChatGPTの理解しているもの」は「文章」という「具象化されたもの」だけであり、「それ以外の事」は何一つ知りません。つまり学習で理解した文章が全てであり、それ以外は一切知りません。そのため当然ですが、「真偽の判断」はできないという事です。
では最後に「5 抽象化/論理能力がない」を説明します。先に説明したようにChatGPTの理解しているものは「文章」という「具象化されたもの」だけです。つまり文章の「単語の意味」と「単語間の関係」更に「品詞」や「構文」という「具象化されたもの」だけです。
これらの具象化された意味の一貫性を維持し、それらの中での「正否の判断」はしても、それらの本質を「価値/原理/手順」として抽出し、それらの本質の一貫性を維持する「論理能力」はないという事です。この事はここまでの説明からも十分ご理解頂けると思います。
では次に「解決策の検討」を説明します。最初に結論から言えば、次の通り、考えています。
1 文章を「手順→原理→価値」と要約できない→〇
2 問題を「価値→原理→手順」と解けない→〇
3 問題を解く知識を教えられてもその通り実行できない→〇
4 真偽の判断ができない→△
5 抽象化/論理能力がない→△
ご覧頂ける通り、1から3は〇、つまり「解決」、それに対して4から5は△、つまり「部分的に解決」と考えています。これらは以降順番に説明します。最初に解決の基本的考えを説明します。これを図から抜粋すると3点です。次に示します。
1 思考の真理(価値→原理→手順の解決の思考力)に基づく
2 既存の枠組みの上に解決の思考力を実行する仕組みを創る
・誤差逆伝搬法により新たな次元と読み込みヘッドの追加
・ファインチューニングにより正解データから実行する仕組みを創る
3 問題を解く知識を問題と一緒にプロンプトとして入力
ご覧頂ける通り、1つは「思考の真理」の「解決の思考力」つまり「価値→原理→手順」に基づく事を前提としています。これは基本となります。
次に2つ目の「既存の枠組みの上に解決の思考力を実行する仕組みを創る」は最初に前提となる基本認識から説明します。
これはいわゆる人間と同じように「思考するAI」は創れないという事です。つまりAIが自ら思考力を有し人間と同じように思考する事は不可能という事です。これが私の基本認識です。この理由を一言で言えば、「思考」とは「思った事を明らかにする事」ですが、これをAIはできないという事です。
何故なら、AIは「感性の右脳」による「思う」という事ができないからです。人間は物を見て様々な「思い」が生まれますが、AIには「思い」が生まれないからです。また「論理の左脳」により「事を明らかにする」ためには「時間」を認識する事が必要であり、人間は年を取り肉体的に成長、衰え、自然に時間を認識していますが、AIは年を取る事はありません。
つまり「感性の右脳と論理の左脳の実践知識」で説明したように「宇宙」には「空間」と「時間」が存在し、それに対応するために「人間」には「空間と物」を認識する「感性の右脳」があり、「時間と事」を明らかにする「論理の左脳」が備わっています。もし、それを人工的に創るとすれば、それは「新たな人間を創る」という事です。これは永遠に不可能です。
但し、既存の枠組みの上に解決の思考力を実行する仕組みを創る事は可能と考えています。ここで既存の枠組みはディープラーニングです。この上に「価値→原理→手順」の解決の思考力を実行する仕組みをディープラーニング自身に創らせる事は可能と考えています。
そのため3つ目として「問題を解く知識を問題と一緒にプロンプトとして入力」する事により「文章問題」も「計算問題」も人間と同じように解けるようになると考えています。但し、ここで新たな課題が現れます。それが「問題を解く知識」です。これをどのようにAIは取り扱うかです。これは以降で説明しいます。
では次に解決策を順番に説明します。
最初に「1 文章を「手順→原理→価値」と要約できない」は「価値/原理/手順」を学習させる事により要約できると考えています。
具体的に言えば、「今日は晴れなので暖かいです」の後に「価値/原理/手順は何かと質問し学習させる事」により可能と考えています。ここで「価値」は「暖かい」であり、「原理」は「晴れ」であり、「手順」は「今日」です。
次に「今日は晴れなので暖かいです→晴れなので暖かい→暖かい」と「要約する事を学習させる事」により「要約」は可能と考えています。ここで「要約」は「価値と原理」または文字数が制限されてれば、「価値」だけです。
尚、このように学習させる事により「次元」には「価値」と「原理」と「手順」と以降で説明するように問題を解く解き時は「解答」が誤差逆伝搬法により追加されると考えています。また読み込みヘッドには「価値ヘッド」と「原理ヘッド」と「手順ヘッド」と「解答ヘッド」が誤差逆伝搬法により追加されると考えています。
次に「2 問題を「価値→原理→手順」と解けない」と「3 問題を解く知識を教えられてもその通り実行できない」は一緒に説明します。これは「問題」と「問題を解く知識」と「正解」により解答を論理的に導くように学習させます。次にこれを「文章問題」と「計算問題」に分けて説明します。
最初に「文章問題」から説明します。この場合「問題」と「問題を解く知識」と「正解」を図から抜粋すると次の通りです。
■問題 「今日は晴れです 上着を脱ぐ人もいます 今日の陽気はなんですか」
■問題を解く知識
・価値として質問文の主語を見つけ (今日の陽気)
・原理として状態を表現する言葉を見つけ (晴れ)
・手順として行為/動作を表現する言葉を見つけ (上着を脱ぐ)
・解答として価値の値を原理と手順を満たすものとして求め主語の値として解答する(暖かい)
■正解 「今日の陽気は晴れで上着を脱ぐ人もいて暖かいです」
ご覧頂ける通り、「問題」は「今日は晴れです 上着を脱ぐ人もいます 今日の陽気はなんですか」です。これに対する「問題を解く知識」は4つあります。
1つは「価値として質問文の主語を見つけ」、2つ目は「原理として状態を表現する言葉を見つけ」、3つ目は「手順として行為/動作を表現する言葉を見つけ」、4つ目は「価値の値を原理と手順を満たすものとして求め主語の値として解答する」です。これにより順番に「今日の陽気」、「晴れ」、「上着を脱ぐ」、「暖かい」が抽出されると考えています。
次に「正解」は 「今日の陽気は晴れて上着を脱ぐ人もいて暖かいです」です。
これらを学習する事により「文章問題」を「価値→原理→手順」と解けるようになると考えています。このポイントは次の5点です。
1 問題を解く知識をニューラルネットはどのように認識、学習するか
2 価値の言葉、原理の言葉、手順の言葉を認識、抽出できるか
3 価値の値というものを認識、抽出できるか
4 抽象化/具象化を認識し、実行できるか
5 論理をを認識し、実行できるか
ご覧頂ける通り、全て本質に関わる事です。そのため最初に基本となる考えを改めて説明します。これは先に説明したように「既存の枠組みの上に解決の思考力を実行する仕組みを創る」です。具体的に言えば、「誤差逆伝搬法による新たな次元と読み込みヘッドの追加」と「ファインチューニングにより正解データから実行する仕組みを創る」です。
次にこの意味を具体的に説明します。最初にご理解頂きたい事は、先に説明したように「文章」という「具象化されたもの」が「ChatGPTの取り扱うもの全て」であり、「抽象化/具象化」や「論理能力」はありません。つまり「抽象化/具象化」と「論理」に基づく「思考力」を実行するものを人工的に創る事は新たな人間を創る事であり不可能です。
但し、ではなぜコンピュータが計算をできるのかと言えば、「IT力」で説明したように「数の真理」を定義そして、それに基づく「計算の真理」と「計算の原理」を発明できたからです。但し、ここでご理解頂きたい事は「コンピュータは人間と同じように計算をしてる」とは認識、理解していません。そうではなく「人間により定義、設計」された「自分の理解している数と計算のやり方」を実行しているだけです。
ここでご理解頂きたい事は「コンピュータの知ってる自分の理解している数と計算のやり方」は2進数と10進数の差はありますが、基本的に人間と同じです。つまり現在のAIのように人間と全く異なるというものではありません。そのため安心して人間はコンピュータを「文明の利器」として活用できます。
さて、ではAIをどうするかですが、これはAI、つまり既存のニューラルネットの仕組の上に「価値→原理→手順」と実行する仕組みを創るという事になります。但し、AIは「具象化されたもの」つまり「文章として表現されたもの」しか理解できませんし、学習できません。そのため「全て正しく表現し、それを学習させる」というのが「基本」となります。
これにより「人間と同じ事」を認識し、学習し、解答を導いてると理解する事ができ、「文明の利器」として安心して使用する事ができます。尚、1点補足すれば、既に何度も説明していますが、AI自身は「誤差逆伝搬法」により学んだ「自分のやり方」で「人間と同じ事」を認識し、学習し、解答を導いています。
その事については「とやかく」言いません。そうではなく「文章により正しく表現された事」を「人間と同じ」ように理解、認識し解答を導く事が大事です。これが「基本の考え」となります。
では次にこの考えに基づいて順番に説明します。最初に「1 問題を解く知識をニューラルネットはどのように認識、学習するか」から説明します。
このポイントは「問題を解く知識」つまり「問題を解く知識を説明する文章」というのはAIにとって「初めて扱う文章」である事です。今までの学習時の文章は「状況を説明し、次の単語を予測する」という「状況説明の文章」と「質問の文章」プラス「正解の単語または文章」だけです。これをどう解くかのやり方は自分のやり方で決定していました。
そのため先に説明したように「やり方を説明する文章」を理解し、それに基づいて問題を解くという事は学習していません。これが「問題を解く知識を説明する文章」はAIにとって「初めての文章」という意味です。ではこれをどのようにAIは取り扱うのでしょう。
これは「案ずるより産むが易し」と考えています。つまり誤差逆伝搬法により「指示されたやり方」を学習してくれると考えています。更に1つ重要な事に気づいてくれると考えています。それは「問題を解く知識」に基づいて言葉を見つけると、「それが正解」になるという事です。この事を誤差逆伝搬法は「問題と問題を解く知識と正解」の「一括りの文章の内部表現」として検出すると考えています。。
そのため非常に重要なのが「問題を解く知識を正確に表現する事」です。ここで誤った事を記述すると、誤った事を無理やり正解に結びつけるという事になり根本的に誤ってしまいます。そのため先にも説明しましたが「問題を解く知識を正しく表現する事」が「価値→原理→手順」と実行する仕組みを創る「基本」となります。
では次に「2 価値の言葉、原理の言葉、手順の言葉を認識、抽出できるか」を説明します。
これは十分できると考えています。理由は「価値/原理/手順」には明確な本質の差があるからです。これを次に示します。
価値:質問文の主題
原理:状況説明文の状態を表現する言葉
手順:状況説明文の行為/動作を表現する言葉
ご覧頂ける通り、「価値」は「文章の主題」、「原理」は「状況説明文の状態を表現する言葉」、「手順」は「状況説明文の行為/動作を表現する言葉」と明確な差があります。そのためAIは「価値/原理/手順の言葉」を抽出できると考えています。
但し、「価値」については「価値の値」があります。これはどうでしょう。では次に3 価値の値というものを認識、抽出できるか」を説明します。
最初に説明の前に、「価値の値」について説明します。これは日常会話で忘れられてる点を正確に表現したものです。どういう事かと言うと、「今日の陽気は暖かいです」と言う時に「忘れられてるの」は「抽象化/具象化」と「論理」です。尚、正確に言えば、「忘れられてる事」を人間は「暗黙知」と理解しています。この一例が既に「アリストテレスの3段論法」で説明した「抽象化」と「具象化」です。次にこれを再掲します。
■「抽象化」
「(ソクラテスを抽象化した)人間は死ぬ(真理)」→「ソクラテスは人間(真実)」→「ソクラテスは死ぬ(結論)」
■「具象化」
「人間は死ぬ(真理)」→「(人間を具象化した)ソクラテスは人間(真実)」→「(人間を具象化した)ソクラテスは死ぬ(結論)」
お分かり頂ける通り、「抽象化」の場合は「ソクラテス」、「具象化」の場合は「人間」という言葉が全体を通じて使用されているため「意味の一貫性」つまり「論理」を維持できます。
ここで「ソクラテス」は「人間を具象化したもの」です。尚、「人間を値」と呼ぶ事は、いささか気が引けますが、このように「何々を具体化したもの」を「値」と一般的に定義します。ではこの定義に基づいて前記の「今日の陽気は暖かいです」を表現するとどうなるでしょう。次にこれを示します。
今日の陽気は(陽気を具象化した1つの)暖かいです
ご覧頂ける通り、前述の「(人間を具象化した)ソクラテス」の通り、「陽気を具象化した1つの」という枕詞が「暖かい」の前につきます。つまり正確に言えば、このようになりますが、人間はそのような面倒臭い言い方をしません。但し、このような「抽象化/具象化」と「論理」が「今日の陽気は暖かいです」には含まれています。この事は言われてみれば、容易にご理解頂けると思います。
さて、七面倒臭く説明しましたが、このような事は人間は「暗黙知」として当然理解しています。そのため「今日の陽気は」と言えば、無意識の内に「陽気の値」として「暖かい」という「具象化されたもの、つまり値」を瞬時に選択し、それを話します。
更に言えば、「今日の陽気は」などと七面倒臭く話さずに「陽気」を省略して「今日は暖かいです」更には「今日は暖かい」、そして「暖かい」と最後は「価値の値」のみを話します。
以上から、「価値の値」というものをご理解頂けたと思います。さて、ここでご理解頂きたい事は、ここまで説明した文章に内在されている「抽象化/具象化」と「論理」が「内部表現」であるという事です。そのため「ディープラーニングの近似解」は「誤差逆伝搬法により如何なる学習データの内部表現も抽出し認識/生成する近似解を求められる」という「真理」の通り、これらは十分学習されると考えています。
その結果、十分「価値の値というものを認識、抽出できる」と考えています。つまり「抽象化/具象化」と「論理」という「内部表現」が文章に内在されてる事をディープラーニング、誤差逆伝搬法は十分学習し、理解し「価値の値」を求める事ができると考えています。
但し、これは先に説明した「5 抽象化/論理能力がない」と矛盾するように見えます。では一体どういう事でしょう。最初に「抽象化/具象化」から説明します。では「4 抽象化/具象化を認識し、実行できるか」を説明します。
既に説明したようにAIは「抽象化/具象化」はできません。そうではなくAIの理解してるのは「文章」という「具象化されたもの」だけです。つまり文章の「単語の意味」と「単語間の関係」更に「品詞」や「構文」という「具象化されたもの」だけです。
では前記の「抽象化/具象化」と「論理」という「内部表現」が文章に内在されてる事をディープラーニング、誤差逆伝搬法は十分学習し、理解し「価値の値」を求める事ができるというのはどういう事でしょう。
これは「全て具体的なもの」として実行されているという事です。つまり「論理的に判断する」のではなく、あくまでも「入力ベクトルの数値」という「具体的なものを計算する事により行う」という事です。
例えば、「晴れ」と「服を脱ぐ」という「アテンション」に基づく「単語間の関係の数値の大小」から「暖かい」という「次の言葉」を予測するという事です。つまり「現在のAIの枠組み」を使用して「数値」という「具体的なもの」の計算により求めるという事です。
但し、それを「自力」で行うのではなく「問題を解く知識の文章」に基づいて行うという事です。これが先に説明した「部分的に解決」の「△」の意味であり、既存の枠組みの上に解決の思考力を実行する仕組みを創るという意味です。
これは論理も同じです。ただ1つ異なる事があります。では次に「5 論理を認識し、実行できるか」を説明します。
最初に「異なる事」から説明します。これは「アリストテレスの3段論法」です。この場合は「抽象化」と「具象化」も含まれていますが、もう1つ含まれているのが「人間は死ぬ」という「真理」や「ソクラテスは人間」という「真実」です。そのためAIは「真理」や「真実」は理解していないので「アリストテレスの3段論法」は取り扱えないという事です。
但し、「価値→原理→手順」という「論理」は先に説明したように「具体的なもの」として取り扱う事ができます。この場合で言えば、「価値の値を原理と手順を満たすものとして求め主語の値として解答する」という文章です。これは「価値と原理と手順」をつなげる文章となっています。これにより明示的に「価値→原理→手順」という「論理」を実行させる事ができます。
具体的に言えば、「服を脱ぐ」という「行為」から「暖かい」という「価値の値」を求めるのは必ずしも「正解」とは限りません。異なる理由で「服を脱いだ可能性」もあります。また「原理」は「問題を解く仕組み」として「価値」を内在していますが、「文章問題」の場合には確認が必要です。「晴れ」という「原理」から「暖かい」を求めるのも必ずしも「正解」とは限りません。北風が吹いてれば「寒い」という事になります。
しかし、「晴れ」という「原理」と「服を脱ぐ」という「行為」が同時に発生するならば、それは「暖かい」と断定できます。つまり「価値→原理→手順」という「論理」で問題を解く事ができます。そして先に説明したように「問題を解く知識」に基づいて言葉を見つけると、「それが正解」になるという事です。そのため「部分的に解決」の「△」という事になります。
お分かり頂ける通り、、「文章問題」を「問題を解く知識」に基づいて「価値→原理→手順」と解いていく事ができます。そのため問題を解く知識を問題と一緒にプロンプトとして入力する事により十分「文章問題」を解く事ができると考えています。
では次に「計算問題」を「問題を解く知識」に基づいて「価値→原理→手順」と解く事を説明します。これを「連立方程式の問題」から説明します。
最初に鍵となる考えを説明します。これは「文章問題」と同じように「価値の値」を求めるという事です。つまり基本的に「文章問題」と「計算問題」を同じ解き方で解きます。これが勘所となります。
但し、「計算問題」は「文章問題」よりも複雑です。「何が複雑か」と言うと、「内部表現」です。これが理解し難いものとなっています。そのため説明の前に「内部表現」について3点説明します。
1つは人間の会話には多くの「抽象化/具象化」と「論理」の「内部表現」が内在されている事です。これは「(ソクラテスを抽象化した)人間」や「(くだものを具象化した)リンゴの数」の「ソクラテスを抽象化した」や「くだものを具象化した」という枕詞からもご理解頂けると思います。
2つ目は基本的に「文章問題」であれ「計算問題」であれ、「ある意図」が内部表現として内在されている、つまり隠されてる事です。これは「問題を解く鍵」です。前述の文章問題で言えば、「服を脱ぐ」という「行為」つまり「手順」です。これにより「原理」の」晴れ」と併せて「暖かい」という「価値の値」を求める事ができます。
これは「計算問題」、具体的には「連立方程式の問題」も同じです。「問題を解く鍵」が説明文章には内在されています。あらかじめ説明すれば、「2つの数を求める事」です。これが「連立方程式の問題を解く鍵」です。これから「連立方程式の問題」と断定でき、「連立方程式の公式」に基いて解けば良い事が分かります。
更に2つ目の「問題を解く鍵」が「連立方程式の公式」の「変数」が「具体的なもの」つまり「具象化されたもの」として表現されている事です。つまり「連立方程式の公式」は「抽象化されたもの」ですが、問題では「具象化されたもの」として表現されている事です。そのため問題を解くには「具象化されたもの」を「抽象化」し「連立方程式の公式」に「形式化」する事が必要です。
つまり「連立方程式」を導くという事です。ではどうやって「連立方程式」を導くかですが、この時、日本人の大きな阻害要因となってるのが「連立方程式」という「言葉」です。この意味は「連立する方程式」であり、煎じ詰めれば、「方程式」です。
では「方程式」はどういう意味かと言えば、「連立方程式」で説明したように「方法」と「過程」を示す「式」です。しかし、これではどのように「連立方程式」を導けば良いのか明示的に分かりません。そのため「連立方程式の公式」に「形式化」する事が大変難しくなります。
しかし、「連立方程式の英語」の「Equation」、「等式」という意味から容易に分かります。つまり「等しいもの」を見つけて「等号」、「=」で結べば良いという事です。そして、これが隠された3つ目の「問題を解く鍵」です。つまり「等しいもの」を見つけて「等号」、「=」で結べば良いというように、つまり「連立方程式の公式」に「形式化」できるように「具象化されたものの数」は表現されている事です。
これを一般的に言えば、「計算問題」は「文章問題」つまり「国語の問題」よりも「内部表現」が複数あり「複雑」ですが、「具象化されたものの数」を「公式の変数」に「抽象化」し「公式の具象化されたもの」として「形式化」する事により問題を解けるという事です。
そのため「文章の内部表現」は画像認識の内部表現とは根本的に異なるという事です。言うまでもなく、人間が画像をどのように認識しているかは分かりません。そのため「画像」にどのような「内部表現」があるのかは分かりません。
しかし、「文章」は「人間の創ったもの」であり、「文章」に「どのような内部表現」があるかを人間は明確に解き明かせる事です。これは如何なる「数学の問題」や「物理や工学の問題」も同じです。全ての問題は人間が創ったものであり「如何なる隠された内部表現」があっても解き明かす事ができます。
要約すると「日常会話」には多くの「抽象化/具象化」と「論理」の「内部表現」がある事、「計算問題」更に「物理や工学の問題」には複数の隠された「問題を解く鍵」が「内部表現」として内在されているが解き明かせる事、最後に「文章」は人間が創ったものであり「問題の文章」であれ、如何なる文章の内部表現も解き明かせる事です。
お分かり頂ける通り、人間は「抽象化/具象化能力」により如何なる文章の「内部表現」も解き明かし「問題」を「価値→原理→手順」と論理的に解いていきます、しかし、AIはそのようにはできません。そのため「問題を解く知識の文章」を全て「具象的なもの」として表現しAIに学習させ解かせるという事になります。これは次の「連立方程式の問題」をAIで解かせる基本知識となります。十分ご理解頂ければと思います。
では次に「連立方程式の問題」の解き方を具体的に説明します。最初に学習時の「問題」と「問題を解く知識」と「正解」を図から抜粋して示します。
■問題
鶴と亀が併せて5匹(羽)います。足の本数は合計で16本です。鶴と亀はそれぞれ何匹(羽)いるでしょうか。なお、亀の足の本数は4本で、鶴の足の本数は2本です。
■問題を解く知識
・価値として質問文の主語の求める2つの数をxとyと定義し
・原理として合計の2つの数に等しくなるようにxとyを主語の属性値と乗算し加算し2つの連立方程式を導き
・手順として2つの連立方程式のxの係数が同値になるような数を乗算し2つの方程式を引き算しxを消去しyを求め、yの値を1つの連立方程式に代入しxを求め
・解答としてxとyを2つの主語の値として解答する
■正解
価値 鶴の数をx
亀の数をy
原理 5=x+y
16=2x+4y
手順 5=x+y に2を乗算
10=2x+2y
16=2x+4y から
10=2x+2y を引き算
6= 2y
y=3
5=3+x
x=2
解答 鶴の数は2
亀の数は3
ご覧頂ける通り、「文章問題」と同じく「問題」と「問題を解く知識」と「正解」により学習させます。尚、これは「思考力」の「連立方程式」で説明した鶴亀算の問題です。これを連立方程式で解く場合を説明しています。
次に「問題を解く知識」も「文章問題」と同じく4つあります。これは「価値として質問文の2つの主語の数(値)をxとyと定義し」、「原理として合計の2つの数に等しくなるようにxとyを主語の属性値に乗算し加算し2つの連立方程式を導き」、「手順として2つの連立方程式のxの係数が同値になるような数を1つの連立方程式に乗算し2つの方程式を引き算しxを消去しyを求め、yの値を1つの連立方程式に代入しxを求め」、「解答としてxとyを2つの主語の値として解答する」です。
ご覧頂ける通り、これらは先に説明したように「価値→原理→手順」と「解いていく知識」を「具象化したもの」として表現しています。これにより既存のディープラーニングの誤差逆伝搬法により構築されたやり方により十分解く事ができると考えています。
むしろ問われるのは「問題を解く知識」は「価値→原理→手順→解答」のやり方を正確に具体的に表現しているかです。このポイントは3点です。1つは「具象化されたもの」を「抽象化されたもの、つまり数(値)」に変換しているかです。これは「価値として質問文の2つの主語の数(値)をxとyと定義し」により十分表現されていると考えています。
2つ目は「原理を導くため」の「等しいものを等号で結ぶ」です。これは「原理として合計の2つの数に等しくなるようにxとyを主語の属性値に乗算し加算し2つの連立方程式を導き」により十分表現されていると考えています。
3つ目はAIが本当に「価値→原理→手順→解答」と解いているかどうかです。これは原理と手順の計算はその前に求めた数/式により行う事により十分為されていると考えています。
最後に「正解」も前記の様に、解答の計算式をそのまま入力し、学習させます。これにより「問題を解く知識」とも照らし合わせて十分学習できると考えています。例えて言えば、現在ChatGPTが行っている「文章」から「プログラム」に変換するのと同じです。但し、「数」を「問題の文章」から検索してくるのが異なります。「定式化」と「計算」は「プログラム作成」と同じです。そのため十分できると考えています。
では最後にまとめとして「構成と学習の概要」と「問題を解かせる時の学習」を説明します。最初に「構成と学習の概要」を説明します。これを次に図に基いて説明します。
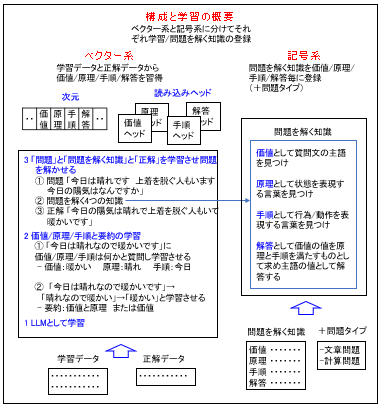
お分かり頂ける通り、先に説明したように「思考するAI」は「ベクター系」と「記号家」から構成されます。これによりベクター系と記号系が連携し解答を「価値→原理→手順→解答」として求めます。
次に「学習の概要」は3段階で行います。最初に従来と同様な学習をLLMに行います。次に価値/原理/手順と要約の学習を行います。つまり先に説明したように
「今日は晴れなので暖かいです」に「価値/原理/手順は何かと質問し、「価値:暖かい」、「原理:晴れ」、「手順:今日」を学習させ、次に「要約」を「今日は晴れなので暖かいです」→「晴れなので暖かい」→「暖かい」の通り、「価値と原理」または文字数が制限されている時は「価値」と学習させます。
最後に「問題」と「問題を解く知識」と「正解」を学習させ問題を解かせます。例えば、先に説明したように「問題」として「今日は晴れです 上着を脱ぐ人もいます 今日の陽気はなんですか」と「問題を解く4つの知識」と「正解」の「今日の陽気は晴れで上着を脱ぐ人もいて暖かいです」を入力し、正しく「価値→原理→手順→解答」と解答できるように学習させます。
このように一般的な文章問題から「価値/原理/手順/解答」という概念や「価値→原理→手順→解答」と答える事を学習させるのが特徴です。これにより「次元」には「価値/原理/手順/解答」また「ヘッド」は「価値/原理/手順/解答」が追加されると考えています。併せて「記号系」には「問題を解く知識」と「問題タイプ」も登録します。これらは人間が作成し登録します。
では次に「問題を解かせる時の学習」を具体的に説明します。これを次に示します。
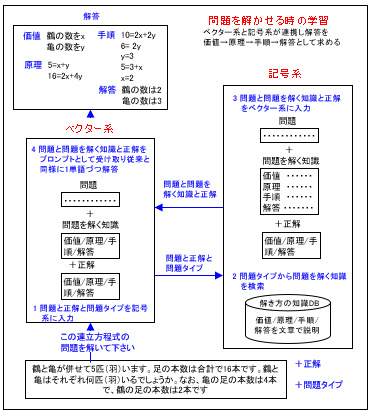
ご覧頂ける通り、ベクター系と記号系が連携し解答を求めます。最初に「この連立方程式の問題を解いて下さい」と指示し「問題」と「正解」と「問題タイプ」をベクター系に入力します。次にベクター系は「問題と正解と問題タイプ」をそのまま記号系に入力します。
記号系では問題タイプから「問題を解く知識」を検索し、次に「問題」と「問題を解く知識」と「正解」をベクター系に入力します。ベクター系では「問題と問題を解く知識と正解」を「プロンプト」として受け取り従来と同様に1単語づつ解答します。
これにより「計算問題」も「文章問題」も「既存のディープラーニングのメカニズム」を用いて「知識」に基づいて正しく「価値→原理→手順→解答」と求める事ができると考えています。そして「知識」を追加する事により永続的に進化すると考えています。
さて、この適用についてですが、「思考するAI」は「コールセンター」や「社内業務知識の継承」や「既存ハードウエア製品の知能化」つまり「自動車の完全自動運転」や「家電製品の知能化」更に「重機やロボットの知能化」更には「建物や交通などの知能化」などあらゆるものに適用できます。
これについては「IT力とAI力の実践知識」で説明します、但し、あらかじめご理解頂きたい事は、これらは全て「特許」に関わる事です。そのため「概要」のみ説明します。
「製品化したい方」は私に問い合わせて頂ければと思います。また「思考するAI」を試作する事は自由にやってかいませんが、「製品化、商用化する時」も私に問い合わせて頂ければと思います。無断で「製品化、商用化する事」は認めません。ご理解を宜しくお願います。
では最後に「まとめ」を説明します。
1.10 まとめ
では「まとめ」を説明します。ここまでお読み頂き誠にありがとうございます。「IT」や「AI」は難解ですが、「真理→原理→価値」と創造されたものを「価値→原理→手順」と理解する「普遍的勉強法」により容易にご理解頂けたと思います。特に「ChatGPTの原理」と「限界」それを打開する「思考するAI」も十分ご理解頂けたと思います。
では次に「IT力とAI力の実践知識」を説明します。
2 IT力とAI力の実践知識
では「IT力とAI力の実践知識」を説明します。さて「IT力とAI力の実践知識」として「解くべき問題の本質を見抜く」→「汎用開発方法/ツールにより開発する」→「知能化製品/サービスを開発する」→「成功AIを開発する」の4つを説明します。
但し、先に説明したように「思考するAI」を活用する後者の2つは「特許」に関係するため概要のみを説明します。あらかじめご理解頂ければと思います。
では次に「解くべき問題の本質を見抜く」を説明します。
2.1 解くべき問題の本質を見抜く
では『解くべき問題の本質を見抜く」を説明します。これは既にご理解頂けると思います。「解くべき問題」が「決定性・非決定性・非可解のどの問題か」を見抜く事です。「問題の本質」を見抜く事がなによりも重要です。
率直に言って、「決定性・非決定性・非可解の問題」を理解せず「コンピュータは何でもできる、更に言えば、AIは何でもできる」と思ってる方が大半だと思います。しかし、そうではありません。「IT/AI」は「非可解の問題」を解く事はできません。これは人間のみが解く事ができます。この事を改めて十分ご理解頂ければと思います。
また既に説明したように「人間の会話・文章」には「抽象化/具象化」と「論理」が暗黙知として内在されています。しかし、それは文章に記述されていないためChatGPTには全く分かりません。ChatGPTに理解できるのは、あくまでも文章に記述された事だけです。
そのためChatGPTの問題を解決するため私は「思考するAI」を発明しました。これにより新たな知識を追加する事により如何なる問題も「価値→原理→手順→解答」と正しく解答する事ができます。この事を今一度ご理解頂ければと思います。
では次に「汎用開発方法/ツールにより開発する」を説明します。
2.2 汎用開発方法/ツールにより開発する
では「汎用開発方法/ツールにより開発する」を説明します。先に「汎用開発方法/ツール」を説明しました。今後は、これに基づいて「アプリ/AI/家電/自動車」を統一的に開発する事がポイントです。
ここでは「汎用開発方法/ツール」により「ディープラーニング」も十分開発できる事を説明します。次に「ディープラーニングのモデリング言語による表現」を示します。
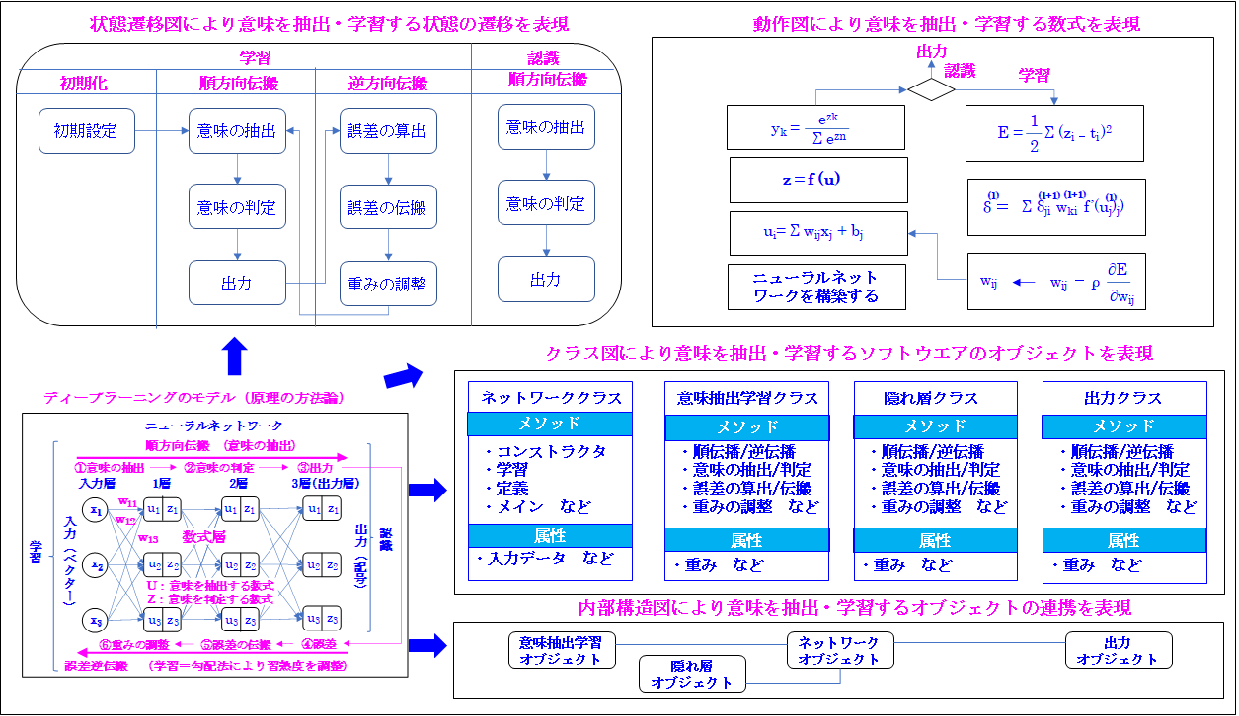
ご覧頂ける通り、「ディープラーニング」も「汎用開発方法/ツール」のモデリング言語により十分る表現できます。
例えば、「ディープラーニングの数学モデル」も「状態遷移図」により十分モデリングできます。これは先に説明した「ディープラーニングの認識の方法論」の①「要素の抽出」→②「要素の判定」→③「出力」→④「誤差」→⑤「誤差の伝搬」→⑥「重みの調整」からご理解頂けると思います。これらは「状態の遷移」です。そのため「状態遷移図」により表現できます。
次に「アルゴリズム」を「動作図」、つまり「アクティビティー図」により表現する事により直感的にご理解頂けます。これにより「プログラム言語」と同じレベルで「アルゴリズム」を表現できます。この利点は「プログラム言語」を知らない一般の方々も容易にご理解、活用できる事です。
最後に「アーキテクチャ」を「構造図」によりモデリングできます。尚、「アーキテクチャ」は「骨格」という「建築用語」ですが、IT業界では「ソフトウエアの構造」という意味で使用します。また、ここでモデリングする構造は「プログラムの構造」であり「ニューラルネットワークの構造」ではありません。
次にモデリング言語では「構造図」は2つから構成されます。1つは「クラス図」、もう1つは「内部構造図」です。そのため「アーキテクチャ」を「構造図」によりモデリングするという意味は「ソフトウエアの構造」を「クラス図」と「内部構造図」によりモデリングするという意味です。十分ご理解頂ければと思います。
では次に「クラス図」を説明します。最初に「アルゴリズム」は7個ありますが、これらを1つのプログラムにすると長くなり「可読性」から問題です。そのため「機能毎」に分割します。ここでは4つに分割します。
これは①「ネットワーククラス」、②「要素抽出学習クラス」、③「隠れ層クラス」、➃「出力クラス」です。
① 「ネットワーククラス」は中心となるもので「メインメソッド」により「実行」を開始します。また「コンストラクタ」により「ネットワークの構造」を定義し、「学習・認識メソッド」により「学習・認識」します。
次に②「要素抽出学習クラス」は前述の「ネットワーククラス」の「学習・認識」の内容を定義します。これは「順伝播/逆伝播」であり、更に「要素の抽出/判定」であり「誤差の算出/伝搬」であり「重みの調整」などです。
そのため「ネットワーククラス」では「要素抽出学習クラス」の「メソッド」が「サブルーティン」のように必要に応じて呼び出され、実行されます。これは「隠れ層クラス」と「出力クラス」の「メソッド」も同じです。これらも必要に応じて「ネットワーククラス」から必要に応じて呼び出され、実行されます。
➂「隠れ層クラス」は「隠れ層(この場合、2層目)」での「順伝播/逆伝播」を実行します。最後に➃「出力クラス」は「解答」を「ソフトマックス関数」により出力します。
尚、「プログラミング言語」ではこれらの「メソッド」はすべて「プログラミング言語」により記述されますが、「モデリング言語」では「動作図」によりモデリングされます。
最後に「内部構造図」はこれらの4つのオブジェクトの連携をモデリングします。これは図に示す通り、「ネットワーククラス」が中心となり3つのオブジェクトと連携している事をモデリングします。
尚、最後に1点補足します。既に説明したように 「いつ何が起きるか分からない自動運転」などの「非決定性の問題」を解くには、「モデリング言語の拡張」が必要です。これは「特許」に関係する事なので、お知りに成りたい方は私の問い合わせて下さるようお願いします。
以上から「モデリング言語」により「ディープラーニングのソフトウエア」も十分モデリングできる事をご理解頂けたと思います。そのため今後は「AI/アプリ/家電/自動車」を統一的に開発して頂ければと思います。
言うまでもありませんが、ChatGPTはプログラムは生成できても「メカやエレキ」の設計はできません。これから改めてSysMLに基づく「汎用開発方法/ツールの有用性」をご理解頂けると思います。
では次に「知能化製品/サービスを開発する」を説明します。
2.3 知能化製品/サービスを開発する
では「知能化製品/サービスを開発する」を説明します。良く言われるように、AIにより「画像・物体」を認識できるようになり、また「言語」も理解できるようになり、「目と耳と頭の一部」を実現できるようになりました。そのため既存ハードウエアは外界を認識し、人間の指示を理解し、「自律的に動作する事」が可能となりました。
このように「機械が認識し自律的に動作する事」を「知能化」と定義します。そのため既存の全てのハードうウエアを「知能化する事」が現実化してきました。しかし、ここで最大の課題は「頭脳」です。「ChatGPTに基づく頭脳」は「嘘をつく事」があります。これでは「機械が勝手」に動作し危険極まりない状況に陥ります。
さて、この問題を抜本的に解決するのが「思考するAI」です。これにより「知識」により正しく動作する事ができます。そのため「知能化の核」となるのが「思考するAI」です。
但し、これを自動車などの分野固有の業務に適用するには「分野固有の技術」が必要となります。そのためこれは「特許」に関わる事であり、非公開とさせて頂きます。実用化したいという方は私に問い合わせて頂ければと思います。何卒宜しくお願い申し上げます。
では次に「成功するAIを開発する」を説明します。
2.4 成功するAIを開発する
では「成功するAIを開発する」を説明します。さてここまでの説明からご理解頂ける通り、「人間の営み」には確実に「成功する方法論」というものがあります。逆に言えば、確実に失敗する「方法論」もあります。しかし、人間にはその事が分かりません。
人生の岐路に立った時、どうすればいいのか、それを導く「解決策」、「成功する方法論」があったとしても、それを調べ、見つけ、適切に決断、行動する事はほとんど不可能です。故に、現実は多くの失敗があり、「勝組」と「負け組」を生み出しています。
これを抜本的に解決するのが「成功するAI」です。これはそのような時に質問し適切な成功例をアドバイスしてくれるものです。そのような事が可能なのかと言えば、可能です。これは「思考するAI」の提供する「成功する知識」により十分可能です。
具体的には、「政府」が「成功するAI」を開発し、国民に「成功知識」を提供する場合と、企業が社内の業務知識を社員に提供する場合の2つを想定しています。
但し、これに「思考するAI」をどのように適用するかは「特許」に関係してきます。そのため非公開とさせて頂きます。実用化される方は私の問い合わせて頂ければと思います。宜しくお願い申し上げます。
では最後に「まとめ」を説明します。
2.5 まとめ
では最後に「まとめ」を説明します。先に説明したように、「思考するAI」を活用するため本節の説明は簡略化したものとなtっていますが、「知能化」や「成功する方法論」という考えはご理解頂けたと思います。また「解くべき問題の本質を見抜く事」や「汎用開発方法/ツール」により「メカ/エレキ/ソフト」を統一的に開発する事をご理解頂けたと思います。
では最後に「結語」を説明します。
3 結語
では「結語」を説明します。ここまでお読み頂き本当にありがとうございます。ITやAIは難解ですが、十分ご理解頂けたと思います。また「思考するAI」により十分日本はChatGPTを超えて行ける事をご理解頂けたと思います。皆様が本ページからIT力とAI力を習得され活躍される事を願っています。
さて、これを持って、本ホームページも終了です。ここまでお読み頂き本当にありがとうございます。皆様が本ホームページから習得された「人間の5元徳」と「普遍的勉強法」そして「正義化によるPM」そして「IT力とAI力」により日本が「世界の工場」から「世界の研究所」に進歩する事をなによりも願っています。
4 皆様へのお願い
尚、トップページからではなく直接このページに来られた方にお願いがあります。本ホームページは一冊の本に相当します。そのため「確かに役に立った」と思われたならば、トップページで説明する私の口座に拙著と同じ金額をお振込み頂ければと思います。何卒、宜しくお願い申し上げます。